 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
[Mitchell] Op 19 April 2019 is de eerste Alpha versie van Crux uitgekomen. Crux is een nieuwe bitemporal database van JUXT. Het is een document store die indexes legt waarmee je graph queries kan uitvoeren op je data. Dit klinkt indrukwekkend maar wat betekent dit nu?
Bitemporality
Om een database bitemporal te mogen noemen moet deze een dingen kunnen opslaan met een valid-time en een transaction-time. Om dit wat duidelijker te maken zal ik een paar voorbeelden geven waarbij we langzaam opbouwen naar een bitemporal database. Bij de meeste projecten waar je gebruik maakt van SQL zul we waarschijnlijk op veel van je tabellen een “Created” kolom toevoegen zoals te zien in Tabel 1.
| ID | Created |
| 10001 | 2019-08-07T09:39:30 |
| 10002 | 2019-10-14T09:39:30 |
| 10003 | 2019-09-20T09:39:30 |
Tabel 1.
Dit is een redelijk pijnloze kolom om toe te voegen want deze timestamp hoef je alleen tijdens de create in te vullen. De volgende stap is om dan een “updated” kolom toe te voegen aan je data model zoals te zien in Tabel 2.
| ID | Created | Updated |
| 10001 | 2019-08-07T09:39:30 | 2019-08-07T09:39:30 |
| 10002 | 2019-10-14T09:39:30 | 2019-10-15T09:39:30 |
| 10003 | 2019-09-20T09:39:30 | 2019-09-25T09:39:30 |
Tabel 2.
Deze updated kolom wordt al vervelender in je data model. Want dit betekent dat je goed moet opletten in je code dat deze kolom iedere keer geupdate wordt. Ook zie je dat je op bijna iedere tabel deze kolommen toe gaat voegen.
Voor sommige werkvelden moet je alle versies van je data bewaren zoals bijvoorbeeld voor de medische of bank industrie. Om dit te bewerkstelligen kan je je tabel opzetten zoals in Tabel 3.
| ID | Version ID | Valid from | Valid to |
| 10001 | 100001
|
2019-01-07… | 2019-03-07… |
| 10001 | 100002
|
2019-03-07… | 2019-08-07… |
| 10001 | 100003
|
2019-08-07… |
Tabel 3.
In dit voorbeeld heeft iedere versie van het document een “Valid from” en een “Valid to” kolom om aan te geven wat in een bepaald versie is van een bepaalde entiteit tussen twee tijdspunten. Misschien valt het hier op dat de 10003 geen “Valid to” datum heeft, dit betekent dat dit de live versie is. Je kan je voorstellen dat deze tabellen toevoegen aan je SQL database ervoor zorgt dat je project heel snel groeit in complexiteit vooral als je deze tabellen gaat querien. Om dit op te lossen zijn er al Temporal databases die dit voor je wegnemen:
- Datomic: bij datomic kan je as-of aanroepen op je database om te querien op je data in verschillende punten in tijd.
- SQL:2011: In de SQL 2011 standaard voor SQL hebben ze support toegevoegd voor temporal databases.
Je merkt hierboven dat ik het heb over Temporal databases en nog niet over Bitemporal databases heb. Bij Temporal databases gebruiken ze de “transactie time” van wanneer je iets in de database stopt. Dus dit betekent dat iedere keer als je iets nieuws toevoegt aan de database de transactie tijd omhoog gaat, zie figuur 1. voor een voorbeeld.
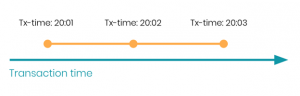
Figuur 1.
Bij Bitemporal databases voegen ze ook een “valid time” toe. Dit zorgt ervoor dat je dingen die in het verleden waren makkelijk kan toevoegen aan de database. Als je kijkt naar Figuur 2. dan zie je dat nog steeds de “transaction time” altijd oploopt terwijl de “valid time” ook terug in de tijd kan.
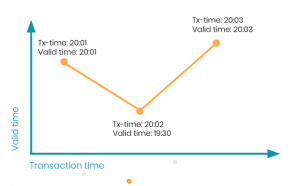
Figuur 2.
Het voorbeeld van Figuur 2. is wat een bitemporal database is. Het grote voordeel van bitemporal databases is dat je vanzelf een transactietijd bijhoudt wat heel erg handig is voor CQRS architecturen, zo wordt het bijvoorbeeld triviaal om naar een transactielog te luisteren en schrijven en lezen op te splitsen. Maar door de “valid time” abstractie kan je nog steeds wel gebruik maken van tijd in je domein. Crux is voor zover wij weten de enige open-source bitemporal database.
Unbundled
Crux noemt zichzelf een “Unbundled database” (Gebaseerd op een artikel van Martin Kleppman). Het is gebouwd met de unix filosofie in het achterhoofd. Het is zo gebouwd dat elk onderdeel doet wat dat onderdeel echt heel erg goed doet. Als je kijkt naar de architectuur van Crux in Figuur 3. dan zie je al dat je voor de Document store en de Bitemporal Graph Indexes kan kiezen voor RocksDB of LMDB. Je ziet dat de transaction en document log gebruik maken van Apache Kafka maar je kan hiervoor bijvoorbeeld ook een JDBC implementatie voor gebruiken. Deze stukken zijn pluggable wij hebben voor een eigen project twee eigen open-source implementaties geschreven namelijk: crux-active-objects
en crux-xodus, zie figuur 4 voor een voorbeeld van hoe dat eruit ziet. Wij hadden dit nodig omdat we bepaalde constraints hadden in dit project. Iets met OSGI maar daar kunnen we beter niet te diep op ingaan. Je krijgt bij alle implementaties dezelfde API.
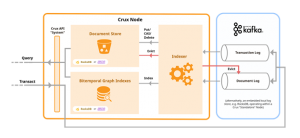
Figuur 3.
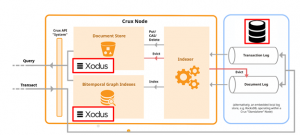
Figuur 4. de nieuwe implementaties zijn rood omlijnd.
Hoe werkt Crux
Crux is een schema-less document store, waarbij je gebruik maakt van transacties om documenten op te slaan. Het opslaan van documenten en het indexeren van documenten is helemaal losgekoppeld. In het voorbeeld van Figuur 3. zie je dat Kafka gebruikt wordt om documenten op te slaan. Je ziet dat de pijl van “Transact” rechtstreeks naar Kafka gaat en dat de “Crux Node” zelf de transacties uit Kafka haalt om deze te indexeren voor queries op de data.
Je ziet bij het Kafka gedeelte van Figuur 3. dat er een “Transaction Log” en een “Document Log” is. In de “Transaction Log” worden alleen transacties opgeslagen met referenties naar content die in de aparte “Document Log” worden bijgehouden. In de “Transaction Log” verwijzen ze naar content checksums die in de “Document Log” staan. Dit is gedaan zodat de transactie log immutable kan blijven. Ze hebben deze dingen ook losgekoppeld omdat we vanwege de AVG wet soms dingen moeten verwijderen uit onze data stores. Ze doen dit door alle versies van een document te vervangen door een marker dat het is verwijderd en ze hoeven niks te veranderen in de transaction log. Standaard houdt Crux alle mogelijk versies van een document bij, maar je kan door middel van een “evict” operatie documenten met al hun versies compleet verwijderen.
Het indexeren van data zodat er queries gedaan kunnen worden is geregeld door Crux. Maar ze hebben niet zelf een nieuwe datastore ontwikkeld ze maken hiervoor gebruik van bestaande Key Value stores. Ze leggen de juiste indexes zodat je datalog queries kan doen op de geïndexeerde documenten, hier gaan we later nog dieper op in. Maar simpel gezegd sla je maps op met data en worden er standaard indexes op alle properties gelegd.
De API
Crux is geschreven in Clojure maar ze bieden ook een Java en REST API aan. We gaan hier in op de Clojure API omdat ze nog bezig zijn om de Java API gebruiksvriendelijker (lees bruikbaar) te maken. Bij Crux ondersteunen ze de volgende operaties:
- PUT
- DELETE
- CAS
- EVICT
Deze operaties worden in EDN (Extensible Data Notation) geschreven. Zie https://learnxinyminutes.com/docs/edn/ voor een sneListl overzicht van EDN.
Put
Een Put operatie ziet er als volgt uit. Iedere operatie is een vector waarbij het eerste element de operatie is. In dit geval is de operatie “crux.tx/put”. Het tweede element in een operatie is de map met data die je wilt opslaan. In deze map kan alles wat valide EDN is opgeslagen worden. De enige voorwaarde is dat er een id word gespecifieerd dit doe je met de key “crux.db/id”, zie ook Listing 2.
| [:crux.tx/put ;; The operation {:crux.db/id :john-mccarthy ;; The id is required :first-name “John” ;; Any valid EDN :last-name “McCarthy” :birth-date “04-09-1927”}] |
Listing 2.
Delete
De delete operatie delete documents bij ID en doet hierbij altijd een soft delete. Dus als ik je iets verwijderd kan je het nog wel in het verleden deze documenten vinden. Je specificeert deletes zoals in Listing 3.
| [:crux.tx/delete ;; The operation :john-mccarthy ;; The id of the document to delete #inst “2011-10-24T09:21:52.151-00:00”] ;; Optional: Deletes the document at the given valid time. If you do not specify this this will be the transaction time. |
Listing 3.
CAS
De CAS operatie doet een compare and swap. Dus het voert een wijziging alleen door als het expected document precies de verwachte waarde heeft. Zie voor een voorbeeld Listing 4.
| [:crux.tx/cas ;; The operation {..} ;; Expected document {..} ;; New document #inst “2018-05-18T09:21:31.846-00:00”] ;; Optional valid time |
Listing 4.
Evict
Evict verwijderd een document en alle eerdere versies. Dit is toegevoegd zodat het makkelijker is om je aan de AVG wet te voldoen, zie listing 5. voor een voorbeeld
| [:crux.tx/evict ;; The operation :john-mccarthy] ;; The id of the document to evict |
Listing 5.
Transacties
Een transactie in Crux is een lijst van operaties zie Listing 6.
| [[:crux.tx/put …] [:crux.tx/put …] [:crux.tx/delete …] [:crux.tx/cas …]] |
Listing 6.
Queries
Voor het querien van data wordt er gebruikt gemaakt van Datalog. Datalog is een logic based query language. Een datalog query bestaat uit een set van variabelen en een set van clausules. Stel je voor dat we de data van Listing 7. in Crux hebben gestopt door middel van drie put operaties.
| [{:crux.db/id :ivan :name “Ivan” :last-name “Ivanov”} {:crux.db/id :petr {:crux.db/id :smith |
Listing 7.
Dan kunnen we een query schrijven zoals in listing 8. Met de query gebeurt het volgende:
- [?id :name ?n] Eerst wordt er door de eerste clausule in the “:where” statement gevraagd om alle documenten die een :name property hebben
- [?id :last-name ?n] Vervolgens zoekt die verder waarbij “?id” wordt hergebruikt uit het vorige statement naar alle documenten die dus een “:name” en een “:last-name” hebben.
- [?id :name “Smith”] Vervolgens maken we set nog kleiner door alleen de documenten te pakken waarbij “:name” een waarde heeft van “Smith”
| {:find [?id] :where [[?id :name ?n] [?id :last-name ?n] [?id :name “Smith”]]} |
Listing 8.
Nu vraag je je misschien af wat dan het resultaat is van deze query. Het resultaat is alles wat gedefinieerd is in de “:find” clausule in dit geval dus alleen een :id zie Listing 9. voor het daadwerkelijke resultaat.
| #{[:smith]} |
Listing 9.
Er is nog veel meer mogelijk met Crux en Datalog maar over alleen deze queries zouden we een compleet artikel kunnen schrijven. Het is in ieder geval ook mogelijk om dat Crux graph queries te schrijven en om terug in de tijd te gaan. De makers van Crux hebben een hele gave tutorial geschreven in Nextjournal die je in de browser kan volgen deze kan je vinden op: https://nextjournal.com/crux-tutorial/start
Waarom Crux
Het is altijd leuk om over nieuwe technologieën te lezen, maar ik ben altijd benieuwd waar je deze dan het beste zou kunnen toepassen. De makers van Crux zijn van origine een consultancy bedrijf. Ze zien bij veel klanten incidentele complexiteit veroorzaakt door ad-hoc temporal en bitemporal oplossingen. Denk aan gigantisch complexe SQL queries of SQL databases die bijna niet op te schalen zijn. Je ziet vaak dat tijd toch wel zo’n essentieel ding is in je datamodellen dat je het vroeg of laat toch moet introduceren in je datamodel. Als een database deze complexiteit kan wegnemen dan kan je je focussen op het probleem wat je probeert op te lossen voor de klant. Ik denk dat de meeste evidente uses cases zijn voor bedrijfstakken waarbij het verplicht is om alle versies van data op te slaan zoals bijvoorbeeld: ziekenhuizen, notarissen, overheid en banken.
De introductie van de AVG wet maakt temporal databases nog een stuk lastiger. In een ideale wereld zou het verleden nooit meer veranderen. Maar in de post AVG wet wereld moet je alle referenties naar bepaalde persoonsgegevens kunnen verwijderen, wat kan zorgen voor een gigantisch aantal updates in de database.
Je krijgt bij Crux standaard een “Event Log” waar je naar kan luisteren om andere views op je data te maken. Wij gebruiken dit bijvoorbeeld zelf om ook bepaalde data te indexeren in Lucene zodat we full-text searches kunnen doen op data. Ze bieden ook sinds kort een Kafka Connect plugin waarmee je de transacties kan publiceren naar een ander topic om bijvoorbeeld rapporten te genereren of data in Elasticsearch te indexeren.
Wij gebruiken Crux zelf voor CRM data, waar het mogelijk is om te zien wanneer een bedrijf van adres veranderd is. Of om te kijken wanneer een persoon ergens anders in dienst is gegaan. Als je geinteresseerd bent in hoe we nu exact Crux gebruiken zie dan ook onze blogpost: https://www.avisi.nl/blog/crux-our-final-database-migration
____________
Over de auteur: Mitchel is als senior full stack developer werkzaam bij Avisi. Hij heft veel kennis over UI development en focust zich met name op development round trips.
Qua architectuur van de software houdt Mitchel zich ook bezig met schalingsproblemen, data-opslag en de development experience. Hij en zijn team maken momenteel applicaties en integraties die veelal draaien op Crux.
Referenties
- Crux
https://opencrux.com/ - Crux Roadmap
https://github.com/juxt/crux/projects/8 - Crux kafka connect
https://www.confluent.io/hub/juxt/kafka-connect-crux - Crux Active objects transaction log implementatie
https://github.com/avisi-apps/crux-active-objects - Crux Xodus key value store implementatie
https://github.com/avisi-apps/crux-xodus - Turning the database inside out Martin Kleppman
https://martin.kleppmann.com/2015/03/04/turning-the-database-inside-out.html