 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Kubernetes [1] bestaat al een tijdje en het kubernetes eco-systeem wordt steeds groter en beter. Om er echter zelf mee aan de slag te gaan, werpt bij veel professionals nog wel wat barricades op. Het is groot en veel en moeilijk en je hebt er van alles voor nodig! Dat kubernetes veel kan moge duidelijk zijn, maar waar begin je nu met leren? In dit artikel gaan we in op de basis van kubernetes en word je meegenomen in hoe je zelf aan de slag kan gaan. We gaan leren dat Kubernetes bestaat uit simpele bouwblokken die gezamenlijk geavanceerde en complexe oplossingen faciliteren.
Auteur: Mark van der Walle
Voor we aan de slag kunnen met kubernetes, is het goed om even terug te gaan wat het precies is. Kubernetes is een open-source uitbreidbaar platform dat zogenaamde containerised workloads en services kan beheren. Het platform faciliteert een flinke hoeveelheid automatisering en het gebruik van declaratieve configuratie.
Maar wat betekent dat nu? Als we kijken naar een simpele REST API verpakt in een container dan laat Kubernetes ons deze heel eenvoudig draaien. Het aanmaken van een instantie van onze API is erg eenvoudig. Het daarna opschalen en neerschalen kan met een simpel commando. Doordat configuratie declaratief is, zorgt Kubernetes dat onze Deployment in de gewenste staat komt. Door het gebruik van Services hoeven we zelf niet meer na te denken over welke Pod waar staat en welke poort gebruikt.
Architectuur
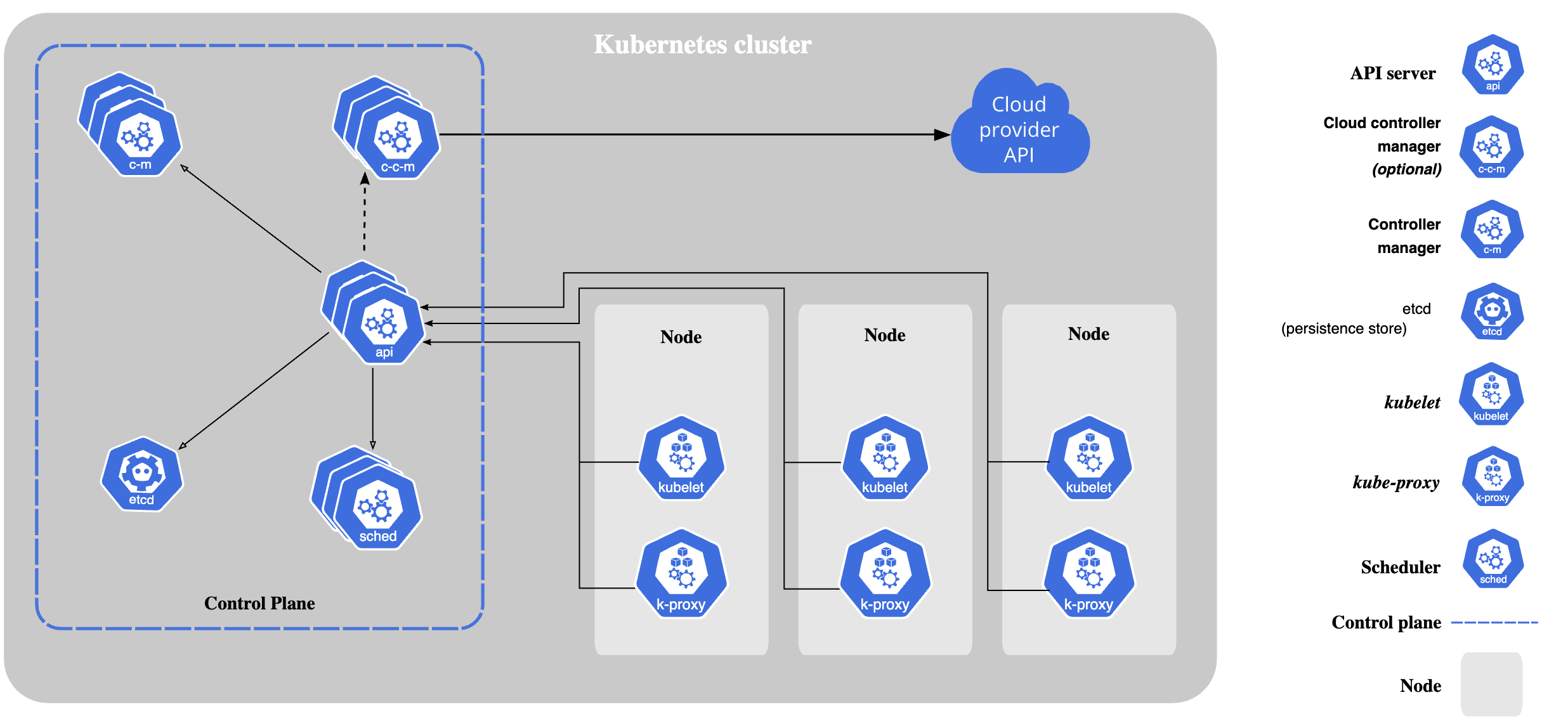
In afbeelding 1 is een hoog over architectuur plaat van Kubernetes te zien. Allereerst is er een Control Plane. Deze zorgt voor het managen van alle workloads en onderdelen die daar bij horen zoals netwerk en configuratie. Naast de Control Plane zijn er meerdere Nodes. Een Node is een VM of een fysieke machine die een aantal processen draait ten behoeve van de containerised workloads.
Control Plane
In de Control Plane draaien een aantal componenten. Allereerst is er controller-manager. De manager houdt continu de staat van het platform in de gaten en onderneemt acties om de gewenste staat te behalen. Een tweede component is de API. De API is dé manier om met het platform te communiceren. De derde component is voor onder andere opslag van de configuratie, meta-informatie en de staat van het cluster. Opslag wordt gedaan in etcd [2]. Als laatste is er de scheduler component. Deze component luistert naar het aanmaken van nieuwe Pods via de API en zorgt dat deze op een van de nodes wordt uitgerold.
Node
Een node is zoals gezegd een VM of fysieke machine dat een aantal processen draait ten behoeve van de workloads. Als eerste is er de Kubelet. Het kubelet proces zorgt ervoor dat containers in een pod draaien en controleert regelmatig de staat. Als de staat niet is zoals deze gewenst is dan kan de kubelet de container opnieuw opstarten, deze verwijderen en een nieuwe maken, een aanpassing doen aan de gekoppelde service en meer.
Het tweede onderdeel is kube-proxy. De combinatie van alle proxies op alle nodes zorgt voor het netwerk van de draaiende workloads. Hierin zitten services, network policies en dergelijke.
De derde benodigde component is de container runtime. Deze is geen onderdeel van Kubernetes zelf, maar dient wel aanwezig te zijn. Traditioneel werd heel veel Docker [3] gebruikt. Echter is Docker een ecosysteem op zichzelf en brengt veel extra mee. Daarom wordt binnenkort Docker als runtime niet meer ondersteund binnen Kubernetes. Er zijn meerdere mogelijkheden voor een alternatief. Kubernetes zelf raad ContainerD [4] aan. ContainerD is een lichtgewichte container runtime.
Kubernetes Objects
We hebben nu een Kubernetes cluster, maar het doet nog niet zoveel. Om nu werkelijk aan de slag te gaan hebben we een container workload nodig. Maar wat betekent dat nu in Kubernetes termen?
Pod
Als je werkt met Kubernetes dan werk je niet rechtstreeks met een container maar met een Pod. De naam pod kan op twee manieren uitgelegd worden. Een groep walvissen wordt wel een pod genoemd. De tweede uitleg komt van peas in a pod. Deze Engelse uitdrukking gaat over hoe erwten in de natuur “verpakt” zijn. Een pod is over het algemeen een container, maar het kunnen er meer zijn. Meestal betekent het dat deze containers niet zonder elkaar kunnen draaien. Dit wordt bijvoorbeeld veel gebruikt bij het sidecar pattern [5].
Deployment
Meestal maak je binnen Kubernetes ook zelf geen pods aan, maar doe je dit via een Deployment. Dit komt omdat een deployment zorgt voor de juiste hoeveelheid pods van het juiste type. In afbeelding 2 is een voorbeeld van een deployment te zien.
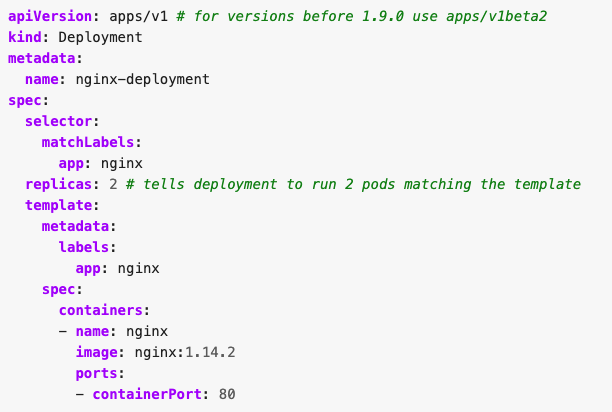
In deze afbeelding zien we in YAML hoe een deployment er uit kan zien. Elk Kubernetes Object heeft een aantal vereiste velden. Deze velden zijn apiVersion, kind, metadata.name en spec. Kind geeft het type aan van het object, in dit geval Deployment. Een apiVersion is de versie van de definitie van het type. Elk object binnen kubernetes heeft een naam. Een naam moet binnen een namespace uniek zijn. In dit artikel gaan we niet verder in op namespaces.
Het laatste onderdeel van een Kubernetes Object is ook het meest interessant. Elk object heeft een spec waarin de gewenste staat van het object staat. Elk object heeft een aantal verplichte en optionele velden in de spec. Deze hangen af van de object definitie.
In deze deployment zien we welke containers er bij deze deployment horen. In de praktijk zullen dit er een aantal zijn die bij elkaar horen. Ook zien we dat er blijkbaar twee instanties van de containers worden gevraagd. Kubernetes zal zorgen dat bij meerdere replicas de containers op verschillende nodes terecht komen. Als laatste geeft de spec per container aan welke container image moet worden gebruikt en welke poort de container opengezet moet worden. Kubernetes biedt uitgebreide mogelijkheden om zelf types te maken. Je kunt deze types dan ook een versie geven.
Service
Een deployment op zichzelf doet nog niet zoveel. De applicatie draait wel, maar hij is niet te benaderen. Zoals we later in het artikel zien is er voor een beheerder wel een mogelijkheid om de container te benaderen.
Denk bij een service aan mapping van een TCP of UDP poort aan een of meerdere containers. Kubernetes kan ervoor zorgen dat de service steeds wordt bijgewerkt als bijvoorbeeld de staat van een pod niet goed is. Services zijn echter alleen binnen het cluster te benaderen.
Zelf aan de slag
We kennen nu hoog over wat Kubernetes kan doen en een aantal simpele bouwblokken om zelf workloads op Kubernetes uit te rollen. Er zijn nog veel meer onderdelen die erbij komen kijken om op grote schaal aan de slag te gaan, maar met de genoemde objecten kan al een begin worden gemaakt om een eigen applicatie op Kubernetes te zetten.
Om zelf aan de slag te gaan zijn er een aantal mogelijkheden. Allereerst is het nodig om een container runtime te hebben. Voor nu is Docker nog steeds het makkelijkst. Voor Windows en Mac kan gebruikt worden gemaakt van de Docker Desktop installatie. Voor Linux hebben de meeste distributies wel een eenvoudige manier om de Docker Engine te installeren.
Als je op Linux zit dan heb je geen Docker Desktop en zul je een alternatief moeten hebben. Hiervoor kun je Kind [6] gebruiken. Kind is een simpele oplossing om snel lokaal clusters te hebben.
Als je van kind gebruik wil gaan maken dan kunnen we een cluster maken met kind. Dit doen we door het commando `kind create cluster`. Kind zal nu het cluster gaan installeren. Kind zorgt er ook voor dat je gelijk via kubectl bent ingelogd en aan de slag kan.
Afhankelijk van hoe je docker hebt geïnstalleerd, kan het zijn dat je nog kubectl nodig hebt. Kubectl is de command line utility om met de kubernetes API te praten. Docker Desktop levert kubectl mee. Kubectl kun je uitspreken als kubecuddle.
Een deployment maken
Met `kubectl get pods` kun je draaiende pods ophalen. Omdat we nog niks hebben gedaan, zal er nu niks draaien.
Door `kubectl apply -f https://raw.githubusercontent.com/Sogeti-Java-Community/kubernetes-examples/echo-server.yaml` uit te voeren wordt er en deployment gemaakt met daarin een container die we dubbel uitvoeren. Als je direct na het vorige commando `kubectl get pods` doet dan zie je dat de pods worden aangemaakt. Met `kubectl get deployments` kunnen we de staat en gewenste staat van de deployment zien.
Pods benaderen met port-forward
Je kunt poorten van individuele pods benaderen met `kubectl port-forward <naam-van-de-pod> 8080:80`. Dit commando start een proxy van lokaal naar de gekozen pod. De naam van de pod kun je vinden door de verschillende pods op te halen. Als je nu in je browser naar http://localhost:8080 gaat, krijg je een echo terug van je verzoek.
Een service koppelen
Met `kubectl apply -f https://raw.githubusercontent.com/Sogeti-Java-Community/kubernetes-examples/main/echo-server-service.yaml` kun je een service maken. Deze is dan gekoppeld aan de eerder gemaakte deployment. Met `kubectl get svc` kunnen we de services ophalen. Dit geeft ook het IP van de service terug.
Een service is alleen benaderbaar vanaf het cluster. Een service ontsluiten van buiten het cluster is wat complexer en buiten scope van dit basis artikel. Om een en ander van binnenuit te testen kun je een debug container starten:
`kubectl run -i --tty --rm debug --image=busybox --restart=Never -- sh`
Nu kun je met bijvoorbeeld wget en het IP uit het service commando de service testen.
Deployments schalen
We kunnen vanuit de cli eenvoudig het aantal replica’s aanpassen door bijvoorbeeld: `kubectl scale deployment –replicas=5 echo-server` als je daarna de pods ophaalt of de deployment bekijkt dan zie je dat de staat van de pods en deployment anders wordt. De service die we eerder hebben aangemaakt wordt automatisch bijgewerkt.
En verder?
In dit artikel zijn we even teruggegaan naar de basis van wat Kubernetes is en hebben we een simpele deployment gemaakt en er een klein beetje mee gespeeld. Op de Kubernetes website [1] zijn veel instructies te vinden.
Referenties
- Kubernetes – https://kubernetes.io/
- ETCD – https://etcd.io/
- Docker – https://www.docker.com/
- Containerd – https://containerd.io/
- Sidecar https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns/
- Kind – https://kind.sigs.k8s.io/
BIO

Mark van der Walle is Lead Software Architect bij Sogeti. Hij houdt zich veel bezig met cloud native development, cloud transities en CI/CD. Daarnaast geeft hij leiding aan het Java Core team van Sogeti en is hij Fellow van SogetiLabs.