 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
A computer program is a nicely ordered flow of instructions, executed one after the other from start to finish… Except when it is not. We often wish to split this flow. Let’s see why and when to do it.
Auteur: Vasco Veloso
So, what’s concurrent programming?
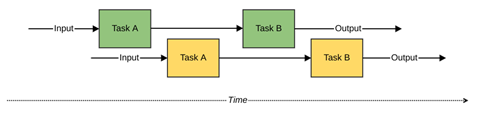
The traditional way of writing programs is to express them sequentially. When one input is received, an output is produced by executing several tasks in order. Then the program becomes ready to process the next input, over and over again (see figure 1).

This way of working matches how machines with a single processing core work. A single processor can only do one thing at a time, so this is the most straightforward method to program on it.
There are drawbacks, however. If any of the tasks need to wait for something, say, a peripheral or the network, then the processor will remain idle during this waiting period. Processing of further inputs will be delayed, thus reducing the overall system effectiveness.
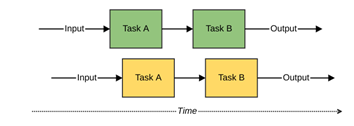
Ideally, processor time could be spent advancing one task for the next input while the processing of the previous input is waiting. This way, a shared resource – the processor – could be used efficiently by different computations. To the human observer, both computations would seem to be performed simultaneously, while in reality, they were being interleaved (see figure 2).
We just defined concurrent computing while barely noticing it. Any two computations are concurrent whenever they share a resource. They don’t occur at the same moment in time, but their lifespans overlap. Concurrent programming is the set of programming techniques that allow us to write programs that work in this manner.
The moment in time when computations happen is a subtle but important detail that allows us to distinguish between concurrent and parallel computing. With parallel computing, computations don’t always share resources and overlap at one or more moments in time.
It follows that we need to employ different physical processors to run some parallel computing. Otherwise, such computations would not be parallel but concurrent. Multi-processor computers and distributed systems are examples of computational hardware that is capable of executing parallel computations. Parallel programming is thus a specialization of concurrent programming, using similar techniques, focused on ensuring that computations occur at the same physical time (see figure 3).
Which operations fit a concurrent model best?
Going back to our task that needs to wait for a resource, we concluded then that processing time was not being used efficiently. Therefore, it is logical that operations that need to wait for something else are prime candidates to be executed concurrently. It does not make sense to run them exclusively in parallel because resources will be wasted anyway whilst barely improving throughput.
Tasks that don’t wait are perfect candidates for parallelism. Think about data processing and mostly calculations. If it doesn’t need to wait nor share resources, it will benefit the most from running in parallel.
Concurrent programming is hard
Concurrency is all about resource sharing. The most evident kind of sharing is writing to a shared data location. A classic example is the bank account deposit problem. If two tasks want to deposit one euro in the same bank account at the same time, money can be lost depending on the way how the independent deposit steps are ordered. This problem is known as a race condition, whereby the outcome is dependent on which concurrent operation finishes first.
Other well-known problems are starvation and deadlocks, which can occur when multiple tasks are sharing a finite set of resources. All tasks may claim resources in such a way that each task still lacks resources to continue: no task makes any progress, which is a deadlock. If only a subset of tasks is blocked from continuing, we say that these tasks are being starved. The dining philosophers problem [2] is a good example of a system study where both problems may happen.
All this goes to show that concurrent systems possess non-deterministic characteristics, i.e., the time and order of operations is not always the same and depend on external conditions. Think about load on a webshop during a sale. The timing of operations is widely different during such peak times. Some defects (like the deposit problem) may cause trouble during these periods and remain harmless the rest of the time. These can be very hard to detect, fix, and test for.
Humans have a hard time wrapping their heads around parallel flows. That being said, [1] helps with further understanding of these fundamental problems related to concurrency.
Implementation styles
The basic premise of concurrency is the interleaving of tasks (see figure 2). To accomplish this on only one computer, some foundation must exist through which such interleaving becomes possible. A construct called a thread was thus developed.
A thread is the smallest unit of execution that can be managed by a hardware platform or operating system. From a physical point of view, one hardware thread corresponds to one CPU core. At the operating system level, threads (or software threads) are managed by a scheduler, which contains a mechanism that executes several threads alternatingly on the same hardware thread.
This is how we can run a very high number of programs on the same computer concurrently: each program correlates to at least one thread. Then these threads share a reduced number of hardware threads, taking their turns in doing their jobs. Without this mechanism for alternating between threads, we would only be able to run concurrently as many programs as the number of CPUs in the computer.
The alternation mechanism can be pre-emptive or cooperative. The former means that the scheduler is free to decide for how long it will allow a thread to run on a hardware thread, whereas the latter means that threads themselves decide when they are ready to yield CPU time (can you see how cooperative systems can be led into starvation?). The difference between pre-emption and cooperation is key when reasoning about concurrency.
Kotlin is a language for the JVM that brings coroutines to the equation: a language construct which allows us to build lightweight concurrent tasks running cooperatively.
Concurrency in Kotlin
Of course, now one question begs to be asked: what are coroutines?
We are all familiarised with the concept of a routine, also called a function or a method. Subroutines mean pretty much the same. But coroutines? They are not the same thing, but they are a deceptively simple concept. Coroutines are routines that cooperate with their execution environment and with each other.
This cooperation happens in the sense that one coroutine can allow the control flow to be transferred to another coroutine without ending the first coroutine. Even potentially switching between execution contexts. Let it sink in for a bit. This unusual definition means that one call from a coroutine to another may cause the original control flow to be suspended, only to resume later, maybe on a different thread.
Suspension in coroutines is similar to suspension in threads. A thread becomes frozen in time and space once it is suspended. Then the OS scheduler selects another thread to unfreeze and resume execution, then suspends it, selects another, and so on until our first thread is selected to resume execution. At this point, it continues as if nothing had happened. The same concept applies to coroutines.
The big difference lies in the mechanics for suspending and resuming.
First of all, suspension in coroutines can only happen when another coroutine is being called, whereas threads can be suspended at any time. This is why we said earlier that a coroutine could “allow” the transfer of the control flow: a coroutine can never suspend if it does not call other coroutines.
Unlike traditional thread-based concurrency, there is no one-to-one relationship between coroutines and threads. So, the thread that was executing a coroutine that got suspended can move on to execute another coroutine. Coroutines are one level of abstraction higher than threads.
All this also means that calls to a coroutine will not necessarily restart its execution, as execution may continue from somewhere in its middle. It all depends on the state of the execution flow. Coroutines are stateful!
Writing coroutines
The Kotlin language supports coroutines, so the compiler and the runtime take care of preserving and passing along the state.
public class App {
private static final Logger LOG = LoggerFactory.getLogger(App.class);
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture.allOf(
CompletableFuture.runAsync(() -> LOG.info("I'm a teapot.")),
CompletableFuture.runAsync(() -> LOG.info("I'm a coffee pot."))
).get();
LOG.info("No more pots.");
}
}
Listing 1
fun main() {
val log = getLogger("main")
runBlocking(Dispatchers.Default) {
launch {
log.info("I'm a teapot.")
}
launch {
log.info("I'm a coffee pot.")
}
}
log.info("No more pots.")
}
Listing 2
Compare the Java code in listing 1 with the Kotlin code in listing 2. Java got better with CompletableFuture after version 8, but Kotlin is more elegant, right? Coroutines were designed to streamline the expression of concurrency in our code.
The results of both listings are equivalent. Both the Java lambdas and the Kotlin coroutines ran concurrently and in different threads. How can we work with Kotlin’s coroutines in practice?
We define a coroutine by using the suspend keyword in its declaration:
suspend fun doSomething(): Unit
This keyword allows the compiler to handle such functions differently. They now need to abide by the rules of coroutines. Rule number one: a coroutine may only be called from within a coroutine scope. Or in other words, from another coroutine.
It may seem like an impossible task. After all, a Kotlin program starts at the main() method, which is a regular subroutine, right? Fear not, some constructs allow us to create an initial coroutine scope.
runBlocking() comes to the rescue. It will take a lambda argument and run it within a coroutine. It will also not exit until the coroutine has completed. This is an essential detail because it is possible to schedule the execution of coroutines in different threads. As such, it is necessary to ensure that the main application thread does not exit until our coroutines have finished. Otherwise, the application would terminate too soon.
Making coroutines concurrent
Earlier, we mentioned that coroutines make it easier to write concurrent code. We must keep in mind that just calling coroutines does not make them concurrent. Even though it is true that each call site of a coroutine is a suspension point, the execution flow is sequential unless stated otherwise. Therefore, we must be explicit and say that we want a given coroutine to run concurrently. We use launch() to do so. Like runBlocking(), it will run a lambda function in a coroutine, but it will not block until its completion. Instead, it launches a child coroutine. The coroutine that called launch() will not complete until all its children do.
All of this becomes clearer if we look back at listings 1 and 2. In Java, we had to list explicitly all the futures we had created to wait for their results. The Kotlin version with coroutines is different. It automatically manages all calls made to concurrent coroutines within the runBlocking() scope.
Coroutine invocations using launch() return an instance of an object implementing Job. This interface represents the running state of a coroutine in Kotlin, like Future represents the running state of an asynchronous task in Java. It is possible to join Jobs just like Futures. However, Job does not allow the caller to consume values returned by a coroutine. Fire-and-forget coroutines have their uses, but coroutines only achieve their full potential as functions when they can return values to their callers.
There is another interface that extends from Job, called Deferred. This interface contains the await() method, which we use to retrieve values returned by coroutines. We obtain instances of Deferred when async() is used instead of launch().
Now we can start coroutines concurrently and work with the values they return. We demonstrate this in listing 3.
suspend fun one(): Int =
withContext(Dispatchers.Default) {
// pretend this is computationally intensive
42
}
suspend fun two(): Int =
withContext(Dispatchers.IO) {
// pretend this is an I/O operation
1
}
fun main() = runBlocking {
val callOne = async { one() }
val callTwo = async { two() }
println(callOne.await() + callTwo.await())
}
Listing 3
Coroutines still need threads
Remember that just like any other code, coroutines need threads to run on: just because we are not creating them ourselves, that does not mean that they do not exist.
Entities known as dispatchers manage the threads allocated to the execution of coroutines. They keep track of which coroutines are running, together with their states, and assign coroutines to threads as necessary. Just like thread pools dedicated to coroutines.
Kotlin supports several built-in dispatchers with different purposes. There is a dispatcher meant for I/O tasks, another to ensure that coroutines run on a thread associated with the user interface, a pre-built thread pool, among others. One should consult the documentation to obtain more details about them since some are platform-specific.
It is possible to assign coroutines to specific dispatchers, and it is often recommended to do so. We can specify the dispatcher as an argument to the launch(), async(), and withContext() functions. Once a dispatcher is defined, by default or explicitly, it will be used by subsequent launch() and async() calls unless these specify a different dispatcher.
Listing 3 demonstrates usage of withContext(): each coroutine runs in a different dispatcher. The caller code gets suspended in each invocation of await() until the respective coroutine finishes.
Looking at listing 2, we see that runBlocking() determined the dispatcher to use. There, it was necessary to define a dispatcher explicitly to ensure that each coroutine would run in a thread other than the main thread. If left undefined, the dispatcher used may be the Unconfined dispatcher: each coroutine will run in the calling thread until they suspend. Because the coroutines in the example never suspend – the logging operation is blocking – then only the main thread would be used.
Dispatcher management can become as complicated as thread pool management. A useful piece of advice is to use withContext() to specify the desired dispatcher. Of course, that would be overkill to do in every coroutine. So, we should use our best judgment and always remember to ask ourselves if the coroutine we are writing can run in any dispatcher or should be constrained to a specific dispatcher.
We may create our own dispatchers, for example, when we want to manage the resources used by a set of coroutines. Or when these need to be segregated from other coroutines due to their runtime characteristics. Usually, this is done by creating an ExecutorService. The dispatcher is then obtained through the asCoroutineDispatcher() Kotlin extension method. No further management on our part is required, except that we must remember to shut down the executor. See listing 4 for an example.
fun main() {
val executor = createExecutor()
try {
runBlocking(executor.asCoroutineDispatcher()) {
getLogger("sample").info("I'm running in a custom dispatcher.")
}
} finally {
executor.shutdown()
}
}
fun createExecutor(): ExecutorService =
Executors.newSingleThreadExecutor {
val thread = Thread(it)
thread.name = "custom-single-thread"
thread
}
Listing 4
Error management
Error management is an essential part of programming. It is relatively simple to reason about error flows in sequential code. However, it can be challenging to foresee all possible error flows once we start to use concurrent patterns.
For example, if we launch three concurrent tasks for one computation, and one of them fails, we need to ensure that all of them have completed before failing the entire computation. Some or all of the others may fail too, even at different moments in time. We must handle all these possible failures. We even want to cancel tasks that have not failed instead of waiting for them to finish, since we already know they became redundant. All this management can add complexity that is unnecessary to the original purpose of the computation.
Structured concurrency is a paradigm whose purpose is to simplify the coordination of concurrent execution flows by enclosing them in execution scopes. These scopes are then handled automatically, terminating only when all enclosed concurrent execution flows reach their completion. In case an error occurs in one of them, all others are cancelled.
fun main() = runBlocking {
suspend fun one(): Int {
println("Answering the most important question in the universe...")
delay(1_000)
println("... done!")
return 42
}
suspend fun two(): Int {
println("Finding the question...")
throw ArithmeticException()
}
try {
coroutineScope {
val first = async { one() }
val second = async { two() }
println(first.await() + second.await())
}
} catch (e: Exception) {
println("Coroutines have thrown ${e::class.java}")
}
}
Listing 5
We want to simulate two non-blocking calculations in listing 5. Here, one of them fails with an exception. The runtime library cancels both coroutines after the failure. Even the coroutine that did not fail is not allowed to run to its completion. The exception is propagated to the code that called await(), so it can handle the error appropriately.
Not only does this make it easier to coordinate the execution of separate concurrent flows, but it also eases the cognitive burden of managing cancellations and failure cases explicitly. Without a structured approach, the overhead introduced by error and cancellation handling requires quite a bit of boilerplate code that distracts us from the real purpose of the computation. Structured concurrency eliminates most of this added complexity.
Is this all?
We do not intend to present an exhaustive description of coroutines in this article. Much remains to be said about them. Instead, we hope to have shown that Kotlin has allowed concurrent code to become more readable by offering first-class support for coroutines. Form no longer obscures the intent. Happy concurrent coding!
Additional reading
[1] https://web.mit.edu/6.005/www/fa14/classes/17-concurrency/ [2] https://en.wikipedia.org/wiki/Dining_philosophers_problem [3] https://docs.oracle.com/javase/tutorial/essential/concurrency/ [4] Alst, Paulien van (2020), Kotlin – Hype of een nieuwe speler op de markt?, Java Magazine, 01 2020, pp 22-24 [5] Subramaniam, Venkat (2019), Programming Kotlin, Pragmatic Bookshelf [6] https://kotlinlang.org/docs/reference/coroutines-overview.html
 Bio
Bio
Vasco Veloso is a polyglot senior software developer, currently interested in software design and architecture with Code Nomads