 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
In september 2019 begon ik als Agile Test Coach bij Simacan. Mijn opdracht? “Verbeter de kwaliteit van het testen.” En wie testen er? De ontwikkelaars; er zijn geen medewerkers die de specifieke rol van tester hebben. De complexiteit van regressietesten in een operationele microservices architectuur is één van de uitdagingen die ontwikkelaars tegenkomen bij het testen. Testautomatisering helpt er natuurlijk bij, om een continu inzicht te krijgen in de kwaliteit van de software. En als het goed opgezet is, kan het ook helpen bij het krijgen van inzicht van de algehele dienstverlening.
In het verleden zijn er, met hulp van externe consultants, al pogingen gedaan voor het opzetten van geautomatiseerde testen. Resultaat: een demo-opstelling die, met behulp van de GUI, een paar functies in de back-end services testen. Het verder aanvullen zou vervolgens door de ontwikkelaars zelf gebeuren. Dit leverde echter al snel problemen op:
- De betrokken ontwikkelaar verliet het bedrijf, waarmee de meeste kennis verdween.
- De GUI testen bleken breekbaar en foutgevoelig. Gevolg: testen werken niet meer.
- Ontwikkelaars werden gedwongen een nieuwe definitietaal te leren om de testen te schrijven.
Om deze problemen het hoofd te bieden kwam ik met een testbeleid dat gebaseerd is op drie pijlers:
– Fast & Continuous: de testen moeten snel en continu terugkoppeling geven aan de ontwikkelaars.
– Multi Purpose: de testen moeten voor meerdere doeleinden bruikbaar zijn (zoals regressie-, performance testen en beschikbaarheidsmonitoring).
– Integrated: de testen moeten geïntegreerd zijn in de dagelijkse werkzaamheden.

De aanvullende wens is om de leercurve voor het maken van de testen zo klein mogelijk te maken, zodat ontwikkelaars het eenvoudig naast hun reguliere werk kunnen bijhouden.
Idee
En zo ontstond het idee van het Simacan Testplatform: een eenvoudig te leren en te gebruiken testplatform, wat continu inzicht biedt in de kwaliteit en beschikbaarheid van de software. Uiteindelijk moeten alle onderdelen van de software, dus front-end en back-end, getest worden middels dit platform.
Echter alles in één keer willen opbouwen, heeft maar één resultaat: mislukking. Daarom besloot ik een aanpak te gebruiken, gebaseerd op drie principes (zie ook afbeelding 2):
– Houd het simpel
– Houd het klein
– Doe het stap voor stap
En uiteindelijk kan het dan best iets groots worden, maar is het opgebouwd uit kleine, simpele en iteratieve stapjes.
Het systeem-onder-test bestaat uit microservices die via API’s en message-buses met elkaar communiceren om zo business-logica via web front-ends aan te bieden. Om het testplatform ook stap-voor-stap te kunnen opbouwen is besloten om eerst het testen van de API’s toe te voegen, gevolgd door support voor de message-bus (Kafka) en als laatste de front-end ondersteuning. Mede omdat wij als bedrijf een verschuiving zien naar API-gebaseerde diensten.
Test Tooling
Dus op zoek naar een oplossing voor automatische regressietesten, beschikbaarheidsmonitoring en performancetesten. Dat klinkt eenvoudig, je kiest een tool, maakt een testscript en voert het uit:
– Voer het éénmalig (enkele gebruiker) uit, controleer de resultaten en je hebt een regressietest.
– Voer het regelmatig uit, kijk of je nog een antwoord krijgt en je weet iets over de beschikbaarheid.
– Voer het met meerdere (gesimuleerde) gebruikers en met een hoge frequentie uit en de basis voor een performancetest is gelegd.
We hadden al besloten te beginnen met de API-gebaseerde back-end services. Die zijn redelijk makkelijk; je stuurt er een HTTP(s)-bericht heen en wacht op antwoord. Meestal zijn die mooi gestructureerd als een JSON, XML of ander formaat. Voor dit soort “testen” kunnen tools als Gatling en JMeter prima als basis dienen. Die versturen en ontvangen HTTP berichten en kunnen ook de inhoud van de antwoorden bekijken. Daarnaast meten ze standaard de tijd die ligt tussen het versturen en ontvangen. Een ander voordeel is dat het beide Open Source tools zijn, die veelvuldig gebruikt worden en goed gedocumenteerd zijn. Oftewel, uitermate geschikt om mee te experimenteren.
Oké, welke tool zullen we dan nemen voor ons testplatform? Deze eerste keuze wordt een gemakkelijke: Gatling is gebouwd in Scala en gebruikt deze taal ook voor het maken van de scripts. Dat verkort tevens de leercurve voor onze ontwikkelaars aangezien onze back-end services ook in Scala zijn gebouwd.
Hosting
De eerste stap is gezet: we hebben de test-tool. Nu op zoek naar een plek om het uit te voeren. Binnen het bedrijf hebben we geen eigen servers. Alles draait in de cloud, ondergebracht bij Amazon Web Services (AWS), waarbij onze microservices gebruik maken van Docker-containers in AWS Elastic Container Services (ECS).
Het is dus logisch om het testplatform ook gebruik te laten maken van deze constructie. We maken dan gebruik van eerdere ervaringen en houden de effort voor onderhoud gelijk zo laag mogelijk. Een bijkomend voordeel is dat zo de test tooling eenvoudig bij de te testen services kan komen, zonder extra instellingen in test- en productieomgevingen.
Hiermee zet het testplatform zojuist zijn tweede stap: het gaat in Docker-containers in de AWS cloud draaien.
Rapporteren
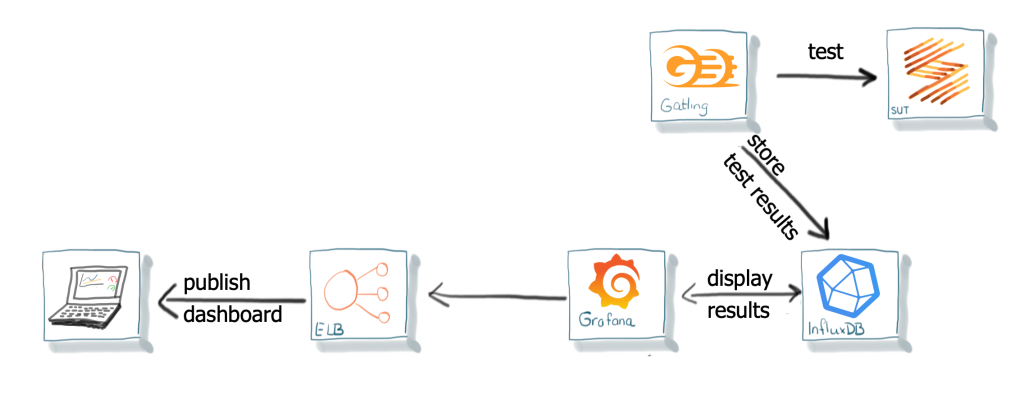
Goed, we hebben de test-tool, we kunnen het ergens draaien en het kan de applicatie of service die we willen testen bereiken. Nu is het zaak de resultaten in te zien. Gatling zelf kan HTML rapporten per test genereren. Dat is prima als je een test afzonderlijk en eenmalig uitvoert. Als de testen, zoals we van plan zijn, regelmatig worden uitgevoerd, dan wil je de resultaten met elkaar kunnen vergelijken. Het hebben van afzonderlijke rapporten is daarbij niet handig.
Het bedrijf achter Gatling biedt hiervoor een oplossing: Gatling Frontline. Dat is een oplossing voor bedrijven om hun performance test suite te beheren, uit te voeren en de resultaten te bekijken. Dat klinkt goed, testen wordt echter per uur afgerekend. Dan lopen de kosten snel op als je 24/7 testen uitvoert. Tevens beperkt het ons in de uitbreiding met mogelijke andere test tools (bijvoorbeeld Selenium of Cypress). We willen namelijk niet alleen performance testen uitvoeren. Tijd om ook eens alternatieven te zoeken.
Een zoektocht op het internet onthult de combinatie van Gatling met Grafana en InfluxDB. Met deze combinatie van Open Source tools moet het mogelijk zijn om met Gatling testresultaten een dashboard te maken. Een opzet gebaseerd op Docker-containers is prima beschreven. Een kleine try-out leert dat het mogelijk is een dashboard te maken waarin de Gatling resultaten getoond kunnen worden. Resultaten tonen en vergelijken kan dus.
Een oplossing voor het bereikbaar maken van de dashboards is binnen handbereik. AWS biedt daar gelukkig een mooie oplossing voor met de Elastic Load Balancer (ELB) die we toch al gebruiken. Daarmee kunnen we de dashboards eenvoudig via internet beschikbaar stellen. Grafana biedt ook nog eens de mogelijkheid om het gebruikersbeheer te koppelen aan onze OAuth provider. Dat maakt het bereiken veilig, afgeschermd en toch eenvoudig voor de ontwikkelaars.
Opslag
Het gebruik van Docker-containers is erg handig voor onderhoud en beheer. Ze zijn alleen vluchtig. Het verliezen van de testresultaten als een container stopt, of het telkens opnieuw maken van een Docker container als een script is gemaakt of aangepast, is niet wenselijk. Sterker nog, dat is een afbreukrisico. Gelukkig bieden zowel Docker als AWS mogelijkheden voor permanente dataopslag. Van alle mogelijkheden die AWS biedt, blijkt Elastic File System (EFS) voor nu de beste oplossing. Het integreert goed met de Docker-containers in ECS en wordt gezien als onderdeel van het filesystem. Hierdoor zijn geen aanpassingen nodig voor Grafana en InfluxDB, terwijl het zorgt dat deze toepassingen herstart kunnen worden zonder dataverlies, zie afbeelding 6.
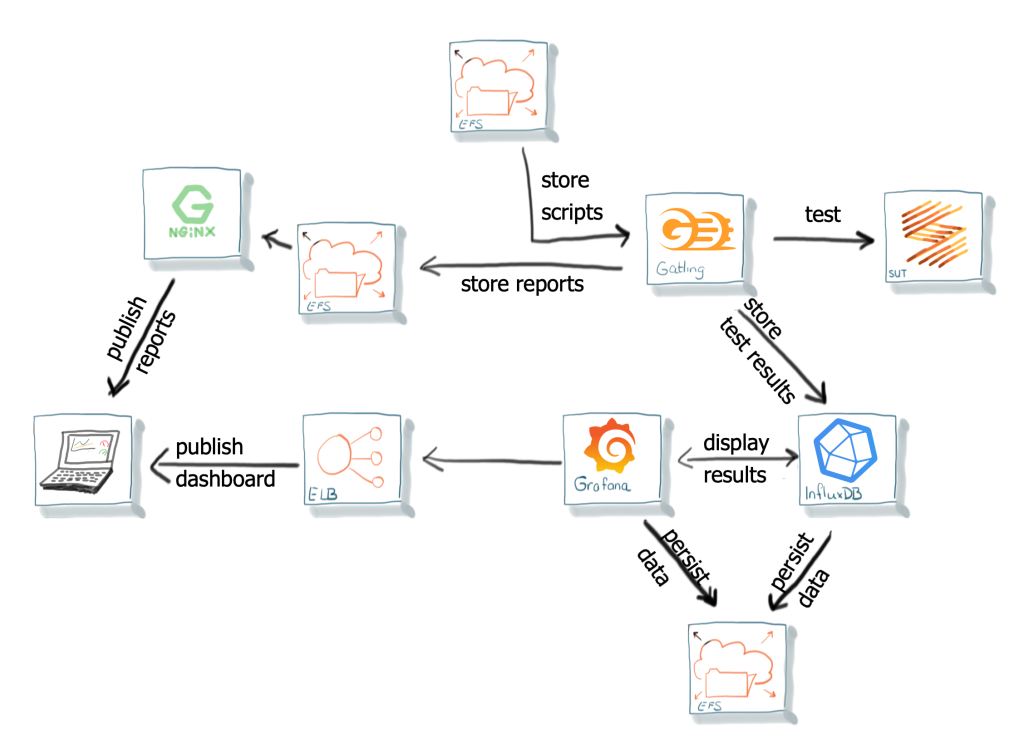
De combinatie van Gatling met Docker-containers biedt ook de mogelijkheid om de Gatling-tool en de scripts van elkaar te scheiden en onafhankelijk te beheren. Als we dan toch al gebruik maken van EFS voor de scripts, dan kunnen we daar ook de testrapporten van Gatling zelf opslaan, mocht iemand die alsnog willen. Een standaard NGINX container biedt hierbij uitkomst om deze HTML gebaseerde rapporten eenvoudig te ontsluiten. Gebruik van AWS S3-buckets zou moeilijker zijn, omdat die minder makkelijk via het filesystem te bereiken zijn, en dus aanpassingen vereisen in de Gatling container.
Uitdagingen
Tot zover loopt het lekker. Alle elementen van het testplatform zijn tot nu toe bestaande componenten. Containers voor Grafana, InfluxDB en NGINX zijn te vinden op DockerHub, aangeboden door de eigenaren van de applicaties. Bovendien is de infrastructuur onder het platform gebaseerd op standaard AWS-diensten, die we al gebruikten. Tijd voor de volgende uitdaging: het herhaald uitvoeren van de testscripts op basis van een tijdschema.
Het idee van het testplatform is, van het begin af aan, veel testscripts zijn, die zeer regelmatig uitgevoerd worden. Ze telkens met de hand starten is geen optie en alle scripts tegelijkertijd draaien, zou een heel grote capaciteit vragen. In de ideale situatie zou het platform alle gereedstaande scripts verzamelen en zodra er capaciteit is: deze uitvoeren. ECS biedt de mogelijkheid om taken volgens een tijdschema uit te voeren, maar houdt hierbij geen rekening met beschikbare capaciteit. Ook moet voor ieder script een eigen taak aangemaakt worden, wat extra onderhoud en beheer vergt.
Binnen het arsenaal van diensten van AWS, kwam al heel snel de optie AWS Batch naar voren. Het biedt de mogelijkheid taken aan te maken, deze in een wachtrij te plaatsen en vervolgens bij beschikbare capaciteit uit te voeren. En doordat meer capaciteit is toe te voegen, is het ook een naar de toekomst schaalbare oplossing.
Dat ziet er goed uit. Het enige wat nog mist is het regelmatig aanmaken van de testtaken, oftewel het plannen. Op het moment van bouwen bood alleen AWS CloudWatch de mogelijkheid AWS Batch taken via een rooster aan te maken. In principe wat we willen, alleen voor ieder script dat gepland wordt, moet zowel een AWS Batch taakdefinitie (Job Definition) als een AWS CloudWatch event worden aangemaakt. Kortom, omslachtig en foutgevoelig. Conclusie: niet echt geschikt.
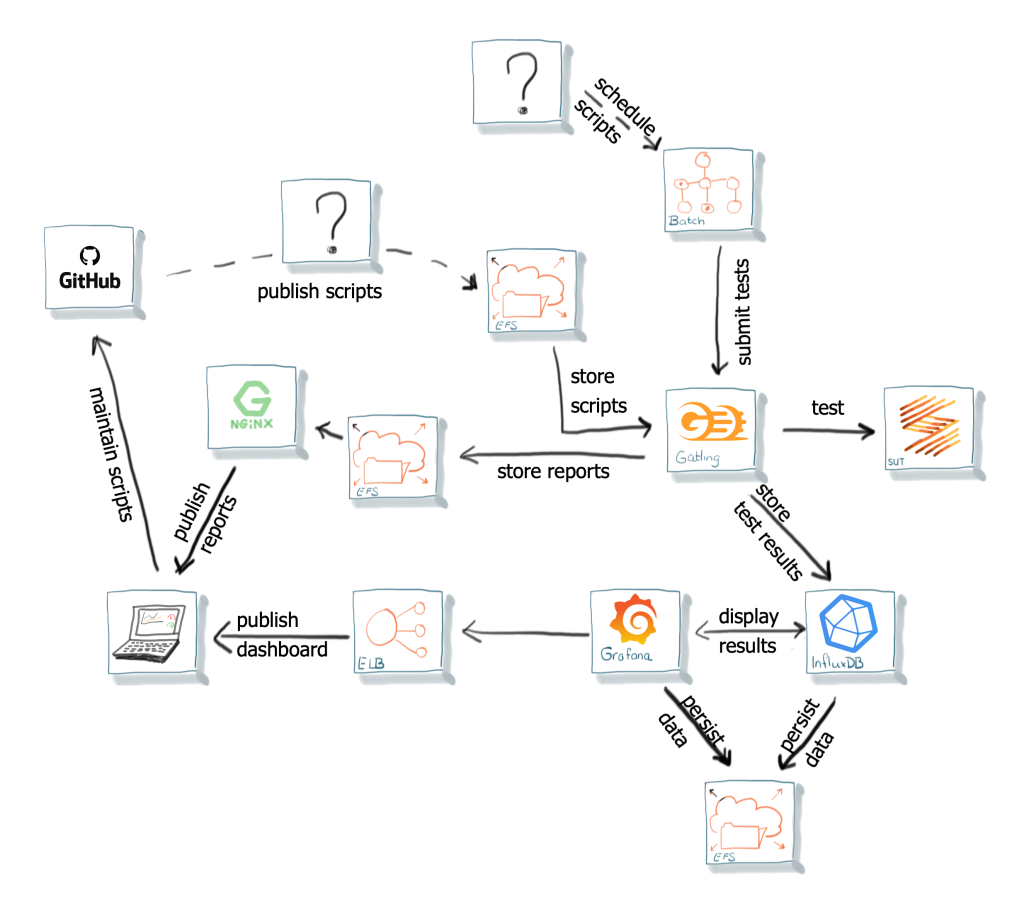
Er is nog een uitdaging: hoe krijgen de ontwikkelaars toegang tot de testscripts? Gatling kan deze via de EFS share wel bereiken, maar om ontwikkelaars allemaal via dezelfde share te laten werken is onpraktisch. GIT in combinatie met Github of Gitlab is zo ongeveer de defacto standaard voor dit soort vraagstukken. En onze ontwikkelaars gebruiken dat al. Versiebeheer van de scripts is op deze manier dan ook gelijk ingericht. Dan blijft er nog over: hoe krijgt Gatling (in zijn Docker container) toegang tot de scripts in Github? De oplossing middels de EFS share was juist zo praktisch en standaard in te regelen, een koppeling naar Github direct niet.
Orchestrator
Dit is het moment waarop de plannen ontstonden om een kleine service, de Orchestrator, te bouwen voor deze twee uitdagingen:
– Een ontvanger voor Github signaleringen (Github Webhooks) om het testplatform te informeren over script-updates: de Github Listener.
– Een planning-service die op basis van een tijdschema de AWS Batch taken aanmaakt.
De Github Listener is het onderdeel van de Orchestrator dat op basis van Github webhook-berichten toetst of er nieuwe versies van de testscripts beschikbaar zijn en deze op de, voor Gatling bereikbare, EFS drive plaatst. De Orchestrator haalt ze daarbij zelf van een vaste afgeschermde plek. Dit voorkomt dat zomaar ieder willekeurig script geplaatst kan worden.
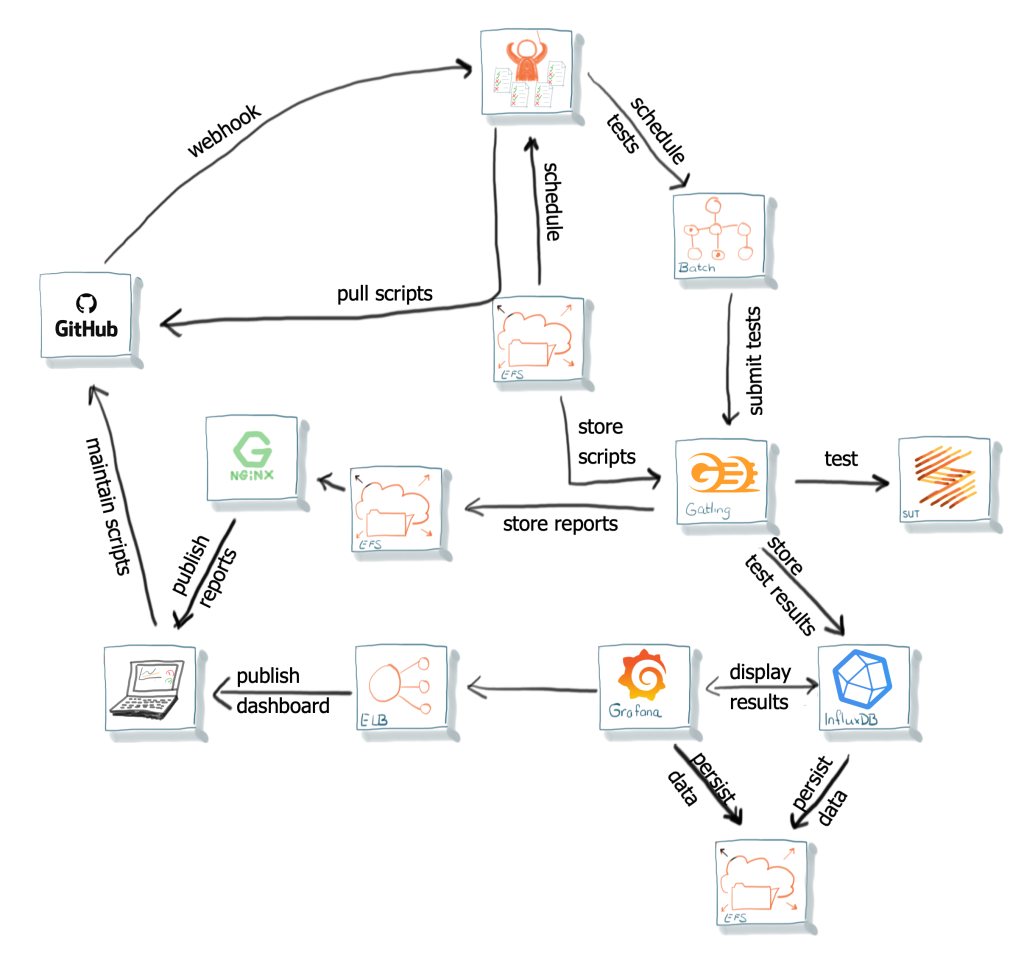
Onderdeel van de gehele script-repository is een schema met daarin de uit te voeren testen. Na het succesvol ophalen van de scripts leest de Orchestrator dit schema en biedt AWS Batch de taken op de gewenste tijden aan. Naast deze planningservice biedt de Orchestrator ook de mogelijkheid testen handmatig te laten uitvoeren en een manier om vertrouwelijke informatie veilig door te geven aan de scripts.
De Orchestrator is in Scala gebouwd, zoals vele andere services binnen ons bedrijf. Noodzakelijk onderhoud en uitbreidingen kunnen daardoor gemakkelijk door de eigen ontwikkelaars worden uitgevoerd. Daarnaast levert de Orchestrator niet alleen een oplossing voor de twee uitdagingen in het testplatform, het dient nu ook als referentieproject voor unit-testen!
Uitbreidingen
Het oorspronkelijke idee achter het platform was: testen uitvoeren, resultaten verzamelen en deze via een dashboard op een groot centraal beeldscherm tonen. Ontwikkelaars met zicht op dat scherm zouden dan gelijk kunnen zien dat testen fout gaan en daar iets mee doen. Dat was het idee…..
En toen was daar Covid-19….. Geen ontwikkelaars meer op kantoor, niemand die naar een groot scherm kijkt en dus niemand die in de gaten houdt of testen fout gaan. Een meer proactieve manier van signalering was dus nodig.
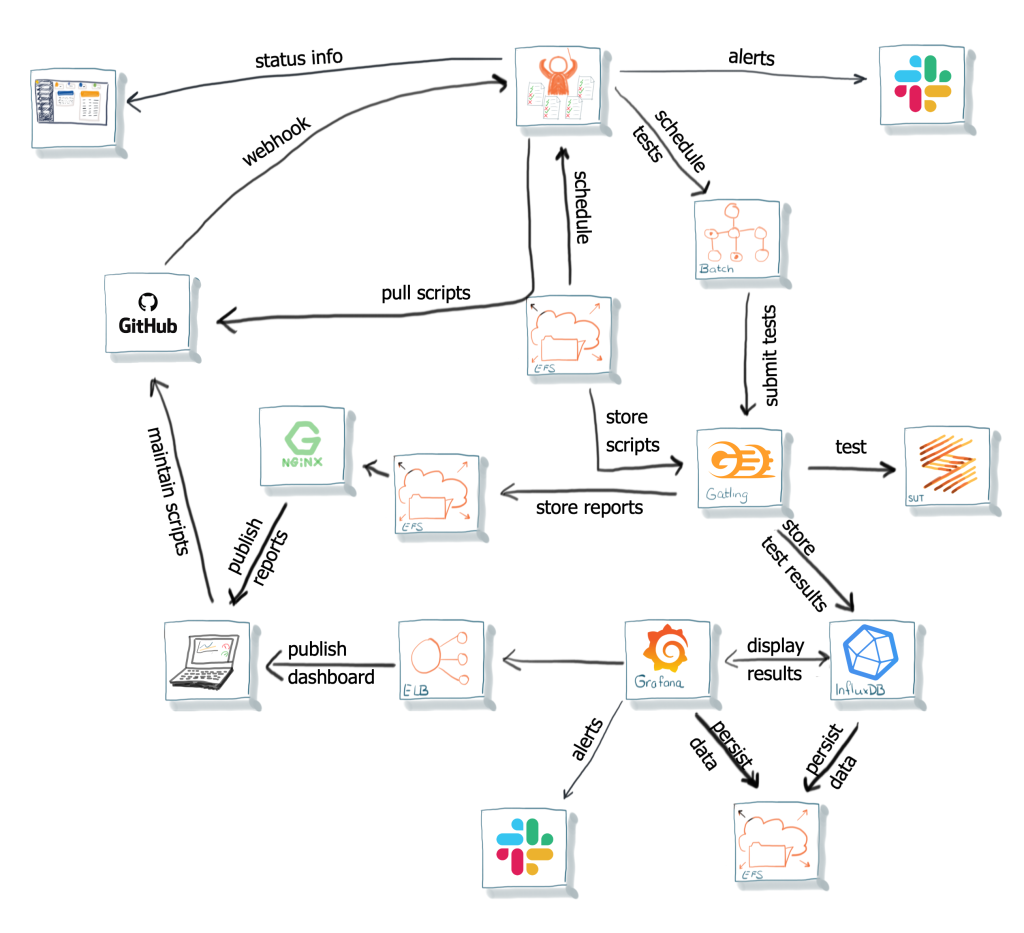
Binnen de ontwikkelteams is het gebruik van Slack, voor berichtenverkeer, al in gebruik. Ideaal is dat, wanneer er testen fout gaan, daar een melding verschijnt. Voor Grafana blijkt dit een out-of-the-box faciliteit te zijn. Alerts gebaseerd op testresultaten kunnen zo naar Slack worden gestuurd. Anders is het voor de test scripts die door een fout geen resultaten naar Grafana sturen. Met andere woorden: hoe worden problemen in de AWS Batch omgeving tijdens de uitvoer van de scripts gemeld? Een uitbreiding van de Orchestrator biedt uitkomst door dit via Slack te melden.
Ook is er een front-end voor het platform gemaakt, die beheerfuncties van de Orchestrator beschikbaar stelt zoals het handmatig starten van testen, individuele testrapporten inzien en versleutelen van vertrouwelijk informatie.
Toekomstige plannen
De basis voor het Simacan Testplatform is nu klaar en werkt. Er wordt gewerkt aan het verder opbouwen van testscripts die zowel voor (keten)regressie, performance testen en monitoring gebruikt worden.
Verder wordt het platform aangepast aan de toekomstige wensen van onze ontwikkelaars, zodat het echt een geïntegreerde plek in hun werkzaamheden gaat krijgen. Voorbeelden hiervan zijn de ondersteuning van Kafka (redelijk uniek gezien het geringe aantal testautomatiseringstools die dat ondersteunen) en de ondersteuning van GUI-testen met Cypress (wat het een multi test tool platform maakt). Hierdoor maken we een volledige regressie-, beschikbaarheids- en performancetestset en -platform.

Bio
Hans Brouwer werkt sinds de jaren ’90 in de IT en heeft ruime ervaring op het raakvlak van Agility en Testen. Daarnaast heeft hij, mede in Azië, ervaring opgedaan in het programmeren van software in meerdere talen en frameworks.