 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Het blijft altijd een beetje tot de verbeelding spreken dat NoSQL het wat minder nauw neemt met consistentie. Het komt wel goed is het mantra. Maar waarom is dat dan zo en hoe wordt hier nu precies voor gezorgd?
Laurens Leeuwis
Cassandra en CQL
Wanneer er razendsnel hoge volumes ongestructureerde data binnenkomen, is een traditionele SQL database vaak niet de juiste oplossing om deze data in op te slaan. Een van de oplossingen in zo’n geval is om een NoSQL database te gebruiken. Cassandra is zo’n database, en valt binnen het NoSQL landschap in de categorie van ‘column families’. Een column family is een verzameling kolommen, eigenlijk een soort (multidimensionale) tabel. Bij rechttoe-rechtaan voorbeelden zijn tabellen en column families dan ook vrijwel inwisselbare termen.
De interactie met Cassandra verloopt in de eigen Cassandra Query Language: CQL. Dit lijkt veel op SQL (zie voorbeelden onderaan), maar is subtiel anders. Zo kunnen er bijvoorbeeld geen JOINS gedaan worden en is een LIKE query ook niet mogelijk. Hierdoor moet je van tevoren precies weten hoe je de data weer uit de tabel wilt halen. Mocht je dezelfde data op verschillende manieren willen consumeren, dan is het verstandig om dit meerdere keren op te slaan, precies zoals je het wilt gebruiken wanneer je het opvraagt. Tijdens mijn praktijkervaring met Cassandra bleek het in eerste instantie lastig om het relationele model helemaal los te laten, voordat we een goede opzet van onze column families hadden gekozen.
Cassandra in de CAP theorie
Cassandra is van de grond af aan opgebouwd om snel en beschikbaar te zijn en zal hiervoor dan ook vaak op meerdere nodes geïnstalleerd worden. Hierdoor krijgen we te maken met de CAP theorie, die stelt dat je nooit ‘Consistent’ (altijd de meest actuele data terugsturen), ‘Available’ (snel antwoorden, hoge volumes aankunnen) en ‘Partition tolerant’ (beschikbaar wanneer een deel uitvalt) tegelijk kunt zijn. Je kunt er wel twee van de drie kiezen. Wanneer we een cluster zouden hebben van twee nodes en de verbinding tussen de nodes valt weg (we zijn partition tolerant) kunnen we available zijn (beide nodes geven hun laatste data terug maar zijn dus niet per se consistent omdat er geen communicatie is tussen de nodes) of consistent zijn (waarbij de nodes bijvoorbeeld geen antwoord meer geven op schrijf-verzoeken en dus niet meer available zijn). Wanneer we niet partition tolerant hoeven zijn, kunnen we wel altijd consistent zijn en antwoorden, maar hebben we een probleem wanneer de verbinding tussen de nodes wegvalt. Cassandra staat binnen deze CAP theorie op de A-P zijde. Hier staat tegenover dat de data ‘uiteindelijk consistent’ is, maar dat dus niet per se direct is.
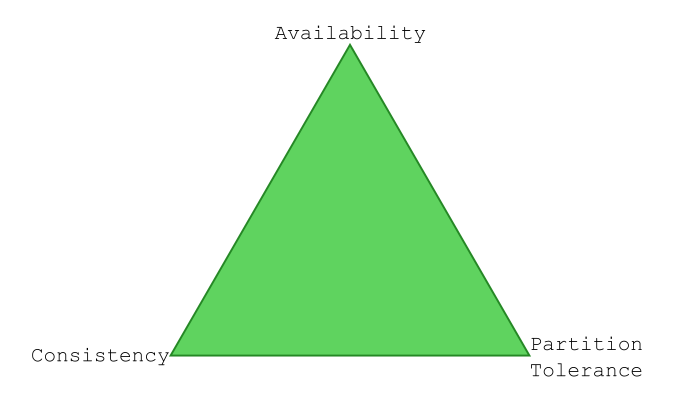
Afhankelijk van de use-case die je hebt is het ‘consistency level’ echter te tweaken. Laten we ons voorstellen dat we een cluster hebben met zes nodes. Voor de keyspace (database) die we gebruiken hebben we gekozen om drie kopieën op te slaan. Stel dat we een use-case hebben waarbij veel geschreven wordt, en weinig gelezen. We kunnen de queries dan zo tweaken dat er al een bevestiging wordt teruggestuurd nadat de schrijfactie gelukt is op één van de kopieën. Wanneer we de query die we doen bij lezen zo instellen dat we van alle drie de kopieën de laatste data terugkrijgen, zijn we toch volledig consistent. We hebben immers de meest recente data.
Bij een use-case waar weinig geschreven en veel gelezen wordt zouden we dit precies andersom kunnen doen. Wanneer er van beide een mix is, kunnen we ook voor een mix kiezen. Wanneer we dit doen verschuiven we in het CAP spectrum echter van de P richting de C zijde: wanneer één van de drie nodes uitvalt zijn we immers niet meer in staat om een bevestiging te krijgen van alle drie de kopieën. Daarnaast moeten we op meer bevestigingen wachten waardoor we iets minder snel kunnen worden. Vaak kiezen we dan ook voor de ‘quorum’ strategie bij het wegschrijven of lezen, waarbij we naar de meerderheid communiceren (bij drie kopieën is dat dus twee). De hoge volumes kunnen we dan nog wel aan.
In de wereld van 24/7/365 en overal ter wereld beschikbaar zijn, hebben we natuurlijk niet met maar één datacentrum te maken. Daarom kunnen we er ook voor kiezen om alleen op ons meest dichtbijzijnde datacentrum weg te schrijven voor we een acknowledge krijgen, of op een meerderheid van de servers per datacentrum te lezen.
Zoals al gesproken gaat dit om de acknowledges. De database is sowieso ‘uiteindelijk consistent’, dus zal altijd alsnog de drie kopieën wegschrijven. Vaak is dit ‘uiteindelijk’ al binnen enkele milliseconden.
Verdelen van de data
In Cassandra zitten allerlei slimmigheidjes om de locatie van de nodes te bepalen. Je kunt dit zelf configureren, maar voor de grote cloud providers zijn er al zogenaamde ‘Snitches’ beschikbaar die het doorgeven. Aan de hand van de locatie van de nodes (in welk rack, in welk datacenter), kan Cassandra vervolgens bepalen waar het handig is om de kopieën slim verspreid op te slaan, zodat er bij uitval toch nog kopieën beschikbaar zijn.
Hoe je je dat voor kunt stellen is dat alle nodes in een slimme volgorde in een soort klok gezet worden. Bij onze 6 nodes zou de eerste node 0 tot 2 uur krijgen, node twee krijgt 2 tot 4 uur, enzovoort. Alle data die wordt opgeslagen krijgt aan de hand van zijn key een tijd toegewezen. Stel dat ‘NLJUG’ de tijd ‘8 uur 17’ krijgt, dan krijgt die dus node vijf toegewezen. Dit is de primaire opslag voor deze data. Omdat we drie kopieën hebben zullen de volgende twee nodes in de klok (node zes en één) een kopie krijgen.

Wanneer je hier meer over wilt weten kun je het beste zoeken op ‘ring’ in plaats van klok. Een node zal normaalgesproken niet één grote range van twee uur krijgen, maar meerdere verspreide kleinere ranges. In realiteit staat er geen tijd op, maar een 64 bits adres. Het omzetten van het woord in een adres wordt gedaan door een ‘Partitioner’. Het is erg belangrijk dat dit uniform gebeurt. Voor de meeste gevallen zal de default Murmur3 Partitioner voldoende zijn, maar wanneer het nodig is kun je ook je eigen Partitioner implementeren en instellen (deze geldt vervolgens wel voor het gehele cluster). Alles is geschreven in Java, en het project is open source.
Connectie maken
Als client kun je met iedere node een connectie maken. Dit is voor jouw request dan de zogenaamde coördinator, die er binnen het datacentrum voor zorgt dat jouw query wordt afgehandeld. Wanneer er met een ander datacentrum gesproken moet worden, zal de coördinator een ‘remote coördinator’ aanwijzen in het andere datacentrum, die daar alles voor je regelt.
De coördinator krijgt vanuit de client de key mee waarvan iets opgeslagen danwel gelezen moet worden. Met de key wordt door de partitioner te gebruiken de plaats op de ring bepaald, en daarmee de nodes die de data bevatten. Bij het opslaan gaat er naar iedere node die de data bevat een schrijfopdracht. Bij het raadplegen gaan er afhankelijk van het consistency level één of meerdere leesopdrachten naar de nodes die de data bevatten.
Schrijven
Wanneer een node een schrijfopdracht binnen krijgt, zal dit allereerst naar de commitlog weggeschreven worden. Deze log staat in de ideale wereld op een aparte schijf, zodat er geen head-movement nodig is van de schijf-kop. Daarnaast wordt dit weggeschreven in een memtable. In een keyspace zitten één of meerdere tabellen. Iedere tabel heeft een eigen memtable.
Wanneer de memtable vol is zal deze naar een immutable bestand weggeschreven worden. Dit bestand heet een sorted-string-table, ofwel ss-table. Hierna wordt de memtable leeggemaakt en wordt er in de commitlog een marker geschreven die aangeeft dat de data tot dat punt in de tijd naar een ss-table weggeschreven is.
Zoals al verteld zijn de ss-tables immutable weggeschreven bestanden. Over de tijd kan de data van een record in veel verschillende van deze ss-tables staan. Het is efficiënter om dit af en toe op te ruimen, een proces wat ‘compaction’ heet. Er zijn verschillende compaction strategieën. Welke het handigste is om te gebruiken is weer afhankelijk van de use-case, de data in de tabel en het systeem dat je hebt.
Lezen
Wanneer er een lees-request komt staat de data mogelijk op veel verschillende plekken: sowieso in de commitlog en in-memory, en dan misschien ook nog eens in één of meerdere ss-tables. Al deze data moet vervolgens gecombineerd worden tot een enkel geheel.
De commitlog wordt in principe niet gelezen. Uiteraard wordt alles weggeschreven voor wanneer er een node uitvalt. In dat geval zal de commitlog gebruikt worden om de memtables te herstellen.
Enkel de data uit de memtable en de ss-tables moet dus gecombineerd worden. De memtable staat in memory en is dus snel en goedkoop toegankelijk. Het moeilijke zit hem dus in de ss-tables. Hier zijn echter verschillende trucjes voor. Allereerst is er voor iedere ss-table een Bloomfilter. Deze Bloomfilter vertelt of een bestand de gevraagde data kàn bevatten. Deze filter kan dus al bestanden uitsluiten, welke vervolgens niet meer bekeken hoeven te worden. Per tabel kan de precisie van deze Bloomfilter ingesteld worden, ook dit is per use-case weer te tweaken.
Er blijven ss-tables over die mògelijk de gezochte data bevatten. Dit kunnen echter enorme bestanden zijn: de maximale celgrootte is bijvoorbeeld meer dan 1 GB. Een ss-table kan dus nog groter zijn. We willen dus niet het hele bestand van voor naar achter door. Hiervoor zijn er indexen op de schijf. Hierin staan de plekken binnen de ring, met daarachter op welke sector op de schijf de data in de ss-table gevonden kan worden. Omdat deze index mogelijk heel erg groot kan zijn, wordt er in-memory een samenvatting van bijgehouden met daarin de positie op de schijf van de index. Hetzelfde trucje wordt dus eigenlijk twee keer gedaan.
Binnen deze stappen kunnen er ook nog caches bijgehouden worden. Zo is er een row-cache waarin de laatst opgehaalde rijen kunnen worden opgeslagen (wanneer meerdere queries om dezelfde data vragen kan deze direct uit cache gelezen worden), en een key-cache. Hierin wordt de index (welke positie in de ring correspondeert met welke sector op de schijf) opgeslagen. Wederom is dit te tweaken, per tabel.
Conclusie
Als je zelf met Cassandra aan de slag gaat kun je al snel van start. CQL (de Cassandra Query Language) lijkt veel op SQL. Om het maximale eruit te kunnen halen is er veel te tweaken. Daarom is het handig om de internals van Cassandra te leren kennen en begrijpen, zodat je weet aan welke knoppen er gedraaid kan worden en wat dit vervolgens doet. Omdat dit per use-case zo goed te tweaken is en direct vanuit CQL gedaan kan worden is het ook aan de developer om hierover na te denken, en niet (alleen) een administrator of infra specialist.
Dat het met consistentie wel goed komt klopt dus, zolang je het het systeem, de keyspaces en de omgeving er maar goed op hebt voorbereid.
CQL voorbeelden
Het maken van een database, binnen Cassandra bekend als ‘keyspace’. Sla drie kopieën van de data op.
CREATE KEYSPACE java_magazine WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’: 3};
Het gebruiken van de database.
USE java_magazine;
Het maken van een nieuwe tabel, waarbij de combinatie van article_title en author uniek moet zijn binnen de tabel en samen onze key vormen:
CREATE TABLE articles (article_title TEXT, author TEXT, issue INT, introduction TEXT, PRIMARY KEY ((author, article_title)));
Kijken wat er aangemaakt is: Hier is onder andere te zien wat voor Bloomfilter instellingen er gebruikt worden, wat de compaction strategie is en hoe de key cache ingesteld is.
DESCRIBE TABLE articles;
resultaat:
CREATE TABLE java_magazine.articles (
author text,
article_title text,
introduction text,
issue int,
PRIMARY KEY ((author, article_title))
) WITH bloom_filter_fp_chance = 0.01
AND caching = {‘keys’: ‘ALL’, ‘rows_per_partition’: ‘NONE’}
AND comment = ”
AND compaction = {‘class’: ‘org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy’, ‘max_threshold’: ’32’,
‘min_threshold’: ‘4’}
AND compression = {‘chunk_length_in_kb’: ’64’, ‘class’: ‘org.apache.cassandra.io.compress.LZ4Compressor’}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = ’99PERCENTILE’;
Data aan de tabel toevoegen:
INSERT INTO articles (article_title, author, issue, introduction) values (‘Hoe slim is Cassandra?’, ‘Laurens Leeuwis’, 201709, ‘Het blijft altijd een beetje…’);
INSERT INTO articles (article_title, author, introduction) values (‘Nog ongeschreven artikel’, ‘Laurens Leeuwis’, ‘Het begon als klein…’);
Data wordt gelezen door op de exacte samengestelde key te zoeken:
SELECT article_title, author, introduction FROM articles WHERE author = ‘Laurens Leeuwis’ AND article_title = ‘Hoe slim is Cassandra?’;
Onderstaande queries werken beide niet, omdat er niet op de gehele exacte key gezocht wordt:
SELECT article_title, author, issue, introduction FROM articles WHERE article_title = ‘Hoe slim is Cassandra?’;
SELECT article_title, author, issue, introduction FROM articles WHERE author = ‘Laurens Leeuwis’;
Het consistency level kan in de interactieve shell CQLSH gewijzigd worden met bijvoorbeeld onderstaande commando’s. Deze consistency levels blijven vervolgens gelden voor alle queries (lezen, schrijven) die je erop uitvoert.
CONSISTENCY one;
CONSISTENCY quorum;
CONSISTENCY all;
Via onder andere de Datastax Java Cassandra Driver kan het gewenste consistency level meegegeven worden bij iedere query die je doet:
QueryBuilder.select().all().from(“articles”).setConsistencyLevel(ConsistencyLevel.QUORUM);