 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Eén van de vier punten uit het Reactive Manifesto is dat software resilient moet zijn. Resilient betekent dat onze software adequaat omgaat met foutsituaties en responsive blijft. Een praktisch en veel voorkomend voorbeeld is een applicatie die gebruik maakt van externe services. In dit scenario is het denkbaar dat deze externe services niet meer beschikbaar zijn of onvoldoende presteren.Zonder maatregelen kan het heel lang duren alvorens dit probleem zichtbaar wordt. Deze traagheid kan er bijvoorbeeld toe leiden dat kostbare resources lange tijd worden gereserveerd, wat kan leiden tot starvation en performance degradatie van de hele applicatie. Niet voor niks stelt dus het Reactive Manifesto dat een applicatie resilient moet zijn.
Failsafe (https://github.com/jhalterman/failsafe) is een kleine library die precies doet wat het moet doen; het toevoegen van resilience aan onze applicatie zonder veel poespas. Failsafe biedt opties voor het opnieuw proberen aan te roepen van een service die kan stoppen met werken. We kunnen ook een fallback gebruiken in het geval dat een service die we aanroepen niet meer beschikbaar is. De library biedt ook de mogelijkheid om een zogenaamde circuit breaker te gebruiken om aanroepen naar services te omzeilen. We kunnen Failsafe gebruiken met Java 6 of hoger. Maar in Java 8 kunnen we lambda’s gebruiken in de Failsafe API voor nette en goed leesbare code.
Setup
Om Failsafe te gebruiken hoeven we niet veel te doen. We moeten de library toevoegen aan het class path van onze software. Het makkelijkst is dat natuurlijk als we een build tool gebruiken als Gradle of Maven. We definiëren een nieuwe dependency voor net.jodah.failsafe met de laatste versie op dit moment 0.9.4.
In het volgende code voorbeeld zien we bijvoorbeeld de definitie voor Gradle:
apply plugin: 'java'
repositories.jcenter()
dependencies.compile 'net.jodah:failsafe:0.9.4'
Laten we nu gaan kijken hoe we de Failsafe library kunnen gebruiken in onze code. Om te beginnen gaan uit van een voorbeeld service die we willen aanroepen. De interface voor deze service staat in het volgende code voorbeeld:
package jdriven;
public interface ExternalService {
String hello() throws ServiceException;
}
Een implementatie van deze interface maakt bijvoorbeeld een aanroep naar een externe web service. Deze externe web service kan traag zijn of zelfs helemaal niet beschikbaar. We gaan kijken hoe we Failsafe kunnen gebruiken om aanroepen naar de hello() method kunnen “beveiligen”.
RetryPolicy
Een belangrijk onderdeel van de library is een abstractie om code meerdere keren proberen aan te roepen als er geen antwoord is binnen een bepaalde tijd. We maken een RetryPolicy object aan. We kunnen aangeven hoe vaak geprobeerd moet worden om code aan te roepen en hoe lang de tussenpozen voor die aanroepen moeten zijn. Ook geven we aan wat de voorwaarde is dat de RetryPolicy gebruikt moet worden. Dit kan een exceptie zijn, maar we kunnen ook ons eigen voorwaarden maken met een Predicate.
final RetryPolicy retryPolicy =
new RetryPolicy()
.retryOn(ServiceException.class)
.withDelay(3, TimeUnit.SECONDS)
.withMaxRetries(5);
Nu moeten we nog de aanroep naar de hello() methode via Failsafe laten verlopen. Hiervoor gebruiken we de Failsafe class die een aantal methoden heeft om een Callable of Runnable implementatie aan te roepen met onze RetryPolicy. Met de get() methode geven we een Callable implementatie op met een return waarde. Met de run() method geven we een Runnable implementatie mee met geen return waarde (void).
In het volgende voorbeeld zien we hoe we onze aanroep naar hello() met een RetryPolicy wordt gedaan:
Failsafe.with(retryPolicy).get(() -> service.hello());
Als we Java 6 of 7 gebruiken is het voorbeeld de volgende code:
Failsafe.with(retryPolicy).get(new Callable<String>() {
@Override
public String call() throws Exception {
return service.hello();
}
});
Er zijn nog wat meer opties die we kunnen configureren voor de RetryPolicy. In ons voorbeeld gebruiken we een vaste waarde van 3 seconden om opnieuw de code aan te roepen bij een fout. We kunnen ook een periode opgeven waarin de tijd tussen elke poging oploopt met de withBackoff() methode.
We kunnen ook een random factor toevoegen aan de intervallen waarin weer wordt geprobeerd of de methode kan worden aangeroepen. Hierdoor wordt de load op de service meer verspreid, waardoor een sneeuwbal effect kan worden voorkomen. Dit geven we aan met de methode withJitter(). Voor elke poging wordt dan een random waarde gebaseerd op de “jitter” waarde opgeteld of afgetrokken van de vaste waarde die wordt gebruikt. Bijvoorbeeld als we de als jitter waarde 100 milliseconden gebruiken dan wordt een random waarde tussen -100 en +100 milliseconden opgeteld bij de periode die is gebruikt om de aanroep opnieuw te doen.
In ons eerste voorbeeld gaven we aan dat maximaal 5 keer opnieuw een poging gedaan moest worden om de de methode aan te roepen. We kunnen ook een maximale periode opgeven waarin nieuwe pogingen gedaan moeten worden met de withMaxDuration() methode.
In het volgende voorbeeld gebruiken withBackOff(), withJitter() en withMaxDuration() om een RetryPolicy object aan te maken:
final RetryPolicy retryPolicy =
new RetryPolicy()
.retryOn(ServiceException.class)
.withBackoff(1, 10, TimeUnit.SECONDS)
.withJitter(200, TimeUnit.MILLISECONDS)
.withMaxDuration(1, TimeUnit.MINUTES);
Circuit breaker
Een circuit breaker zorgt ervoor dat alle aanroepen naar een methode omgeleid worden als de service niet beschikbaar is. Denk aan je eigen elektrische groepenkast met schakelaars. Als een schakelaar is omgeslagen door overbelasting is de stroom eraf. We moeten de schakelaar omzetten om de stroom weer te laten werken. De schakelaar is de circuit breaker, dus als de schakelaar is doorgeslagen staat de circuit breaker open en kunnen er geen aanroepen via de circuit breaker lopen.
Het grote voordeel van het gebruik van een circuit breaker is dat je gebruikers minder lang hoeven te wachten op een foutmelding en er geen overbodige resources worden besteed aan het uitvoeren van verzoeken die uiteindelijke falen. Als we namelijk al weten dat we van de service geen antwoord krijgen, kunnen we beter meteen falen (of terugvallen op een alternatief, maar daarover verderop meer).
Een aanroep met een circuit breaker configuratie via Failsafe zal het circuit open zetten als de service niet beschikbaar is. Na een periode zal Failsafe proberen of de service weer beschikbaar is. Als dat zo is dan wordt het circuit weer gesloten en wordt de service voor volgende aanroepen weer beschikbaar. Als een aanroep plaatsvindt via een circuit breaker die open staat dan wordt de CircuitBreakerOpenException door Failsafe gebruikt om dat aan te geven.
In het volgende code voorbeeld definiëren we een CircuitBreaker. De CircuitBreaker gaat open, zodra éénmaal de ServiceException is opgetreden. Daarna wordt na 10 seconden geprobeerd of er een geldige waarde terugkomt. Het circuit staat dan half open. Half open betekent dat de circuit breaker eerst een gedefinieerd aantal keer goed moet werken, voordat de status weer open wordt. Als in de half open status er weer een fout optreedt gaat de circuit breaker weer dicht. Je kan stellen dat in de status een recovery strategie is om automatisch een service geleidelijk aan weer in gebruik te stellen mits deze voldoende presteert.
Het volgende diagram van Martin Fowler (http://martinfowler.com/bliki/CircuitBreaker.html) geeft de verschillende status opties weer voor een circuit breaker:
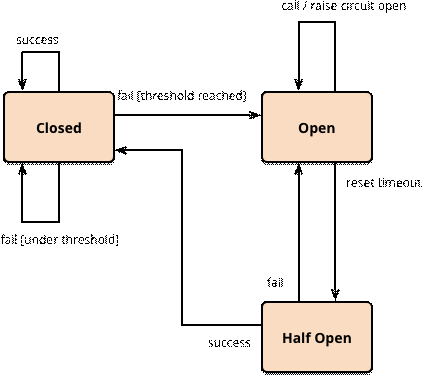
In ons voorbeeld geven we aan dat vijf keer de aanroep gelukt moet zijn en dan is het circuit weer helemaal open.
final CircuitBreaker circuitBreaker =
new CircuitBreaker()
.failOn(ServiceException.class)
.withFailureThreshold(1)
.withDelay(10, TimeUnit.SECONDS)
.withSuccessThreshold(5);
Om de CircuitBreaker te gebruiken voor onze methode aanroep naar hello() gebruiken we weer de Failsafe class, net als bij de aanroep met een RetryPolicy, zoals in het volgende voorbeeld:
Failsafe.with(circuitBreaker).get(service::hello);
We kunnen ook een RetryPolicy gebruiken bij de aanroep. Als de RetryPolicy niet slaagt, dan is dat een voorwaarde voor de CircuitBreaker om het circuit te openen.
Fallbacks
We hebben nu een duidelijk manier om een methode aanroep af te schermen met een RetryPolicy en/of een CircuitBreaker. Als de aanroep dan nog niet lukt dan maakt Failsafe een FailsafeException om aan te geven dat de aanroep niet lukt. Deze exception is een RuntimeException, dus we kunnen zelf bepalen waar we hem afvangen en wat we er mee doen. Maar we kunnen ook een fallback definiëren voor de aanroep. Een fallback is een alternatief voor de echte service aanroep en die wordt gebruikt als de echte service aanroep faalt. We kunnen bijvoorbeeld een backup service hebben we aanroepen. Of we kunnen een goede default waarde teruggeven bij de aanroep. Het is ook mogelijk om zelf een exceptie in een fallback te gebruiken, zodat de aanroepende code die exceptie moet afvangen.
We voegen een fallback toe met de withFallback() method van de Failsafe class. In het volgende code voorbeeld geven we een default waarde terug als de hello() method niet aangeroepen kan worden na een voorgedefinieerde RetryPolicy:
Failsafe
.with(retryPolicy)
.withFallback("default")
.get(service::hello);
Events
Fallback biedt verschillende methoden om bijvoorbeeld te kunnen loggen, wanneer een poging wordt gedaan om een service aan te roepen, de hoeveelste poging die wordt gedaan en of het succesvol of niet was.
Allereerst kunnen we de get() en run() methoden gebruiken met een ContextualCallable en ContextualRunnable interface implementatie. We hebben dan toegang tot de ExecutionContext van Failsafe. We kunnen bijvoorbeeld zien hoe vaak een poging wordt gedaan, de start tijd en hoeveel tijd is gebruikt.
Failsafe
.with(retryPolicy)
.get(context -> {
log.debug("Aanroep {}, start {}, verstreken tijd {}",
context.getExecutions(),
context.getStartTime().toSeconds(),
context.getElapsedTime().toSeconds());
return service.hello();
});
Failsafe genereert ook verschillende events als een aanroep wordt gedaan via Failsafe. Bijvoorbeeld als een aanroep is gelukt of mislukt dan kan met een listener het event worden afgevangen en worden afgehandeld. Bijvoorbeeld een log statement met de informatie uit het event of met de with(Listener) methode tellers bijhouden met metrics en deze gebruiken om de externe service te bewaken. De library is zo opgezet dat je zelf listeners kan definiëren en injecteren (net als een policy) voor aanvullende functionaliteit. Ook een CircuitBreaker ondersteunt events als de status verandert.
In het volgende voorbeeld zien we verschillende event listeners die we kunnen gebruiken:
// Log aanroepen via Failsafe met RetryPolicy.
Failsafe
.with(retryPolicy)
.onComplete((result, failure) -> log.debug("Aanroep gelukt"))
.onFailedAttempt((result, failure) -> log.warn("Aanroep niet gelukt"))
.onRetriesExceeded(context -> log.error("Maximum retries overschreden"))
.get(service::hello);
// Log CircuitBreaker events.
circuitBreaker.onClose(() -> log.debug("Circuit breaker is CLOSED"));
circuitBreaker.onOpen(() -> log.warn("Circuit breaker is OPEN"));
circuitBreaker.onHalfOpen(() -> log.info("Circuit breaker is HALF OPEN"));
Conclusie
Failsafe is een kleine library die precies doet wat je ervan mag verwachten. De API is duidelijk en overzichtelijk. Hierdoor is het ook niet moeilijk om deze library toe te voegen aan je project, zodat je software weer een stuk meer resilient kan worden.