 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Het Kadaster stelt zijn data beschikbaar aan eenieder die er iets mee wil doen. Dit gebeurt via verschillende kanalen. Het Kadaster Dataplatform, de dienst waarbij ik Java ontwikkelaar ben, ontsluit data via publiek beschikbare API’s. Als Kadaster Dataplatform team zijn we hard op weg richting Continuous Delivery. Eén van de precondities hiervoor is voldoende en geautomatiseerde testdekking. Een andere pijler is het testen van de volledige applicatie life cycle, inclusief het bouwen, deployen en configureren van de applicatie. In dit artikel zal ik toelichten hoe wij Docker Compose hebben geïntegreerd in onze Jenkins Delivery Pipeline, en hoe dit voor ons een enabler is voor Continuous Delivery. Mijn doel met dit artikel is je te inspireren zelf aan de slag te gaan met Docker Compose, omdat ik er van overtuigd ben dat je hiermee Continuous Delivery sterk kan vereenvoudigen. In dit artikel ga ik ervan uit dat je bekend bent met Docker, Compose zal ik nader toelichten.
Peter van ‘t Hof
Context
Het Kadaster waarborgt de rechtszekerheid in Nederland: wat is van wie en waar lopen de grenzen. Deze gegevens bieden houvast. Of je nou wilt weten waar je tuingrens loopt, de schutting staat of wat de beste route is voor een snelweg. Gegevens helpen bij het maken van keuzes.
Het Kadaster beheert enorme datasets met data die teruggaat tot de vóór de oprichting van het Kadaster in 1832. Een voorbeeld is de Basisregistratie Adressen & Gebouwen (BAG) met gegevens van alle adressen en gebouwen in Nederland, zoals bouwjaar, oppervlakte, gebruiksdoel en locatie op de kaart, inclusief wijzigingen door de tijd heen. De BAG bevat momenteel meer dan 20 miljoen objecten.
Als overheidsinstantie hanteert het Kadaster een open databeleid: Kadaster data wordt ter beschikking gesteld aan een ieder die er iets mee wil doen. Dit gebeurt via verschillende kanalen. Voor het API kanaal ontwikkelt het Kadaster een platform waarop ze zijn data kan aanbieden met open API ‘s: het Kadaster Dataplatform.
Het Kadaster Dataplatform is (vanzelfsprekend) primair in Java opgezet, en bestaat uit een 10-tal Docker containers waar technologie is ondergebracht als spring-boot, Elasticsearch, Kibana, GraphDB en Swagger / OpenAPI componenten (afbeelding 1).
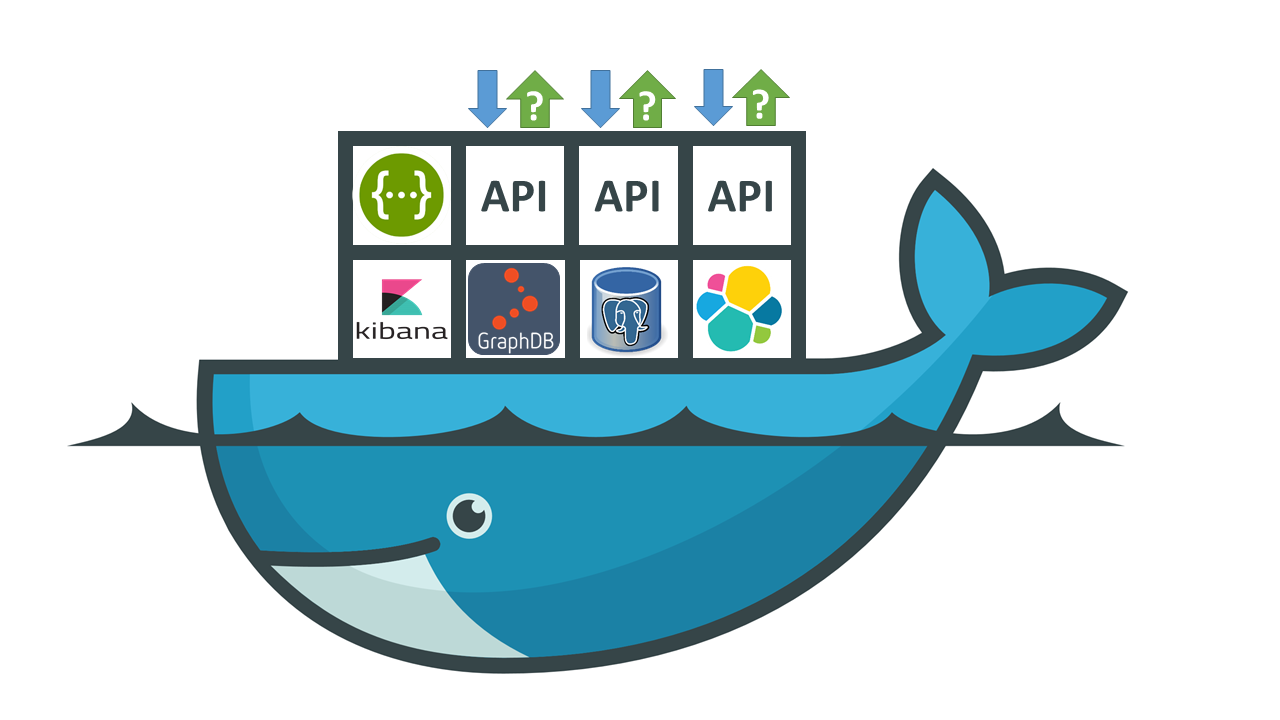
Afbeelding 1
Als team willen we graag richting Continuous Delivery (https://youtu.be/ahRTgG1rEXo). Eén van de precondities om dit goed in te kunnen richten is voldoende, geautomatiseerde testdekking. Daarom zetten we bij het Kadaster zwaar in op testautomatisering, zowel onderin de test piramide (unit tests) als bovenin de piramide (functionele testen) (https://martinfowler.com/bliki/TestPyramid.html).
Onder functionele testen verstaan we bij Kadaster Dataplatform testen op de API: we stellen de API een vraag en controleren het antwoord met het verwachte resultaat. De functionele testen zijn voor het Dataplatform van levensbelang, omdat ze het platform testen vanuit het oogpunt van de gebruiker van onze API ‘s. Onder water raken de testen alle componenten, zowel aan de voorkant (de API ‘s) als achterkant (opslag). De functionele testen controleren daarmee dus ook of de componenten correct integreren met elkaar.
De functionele testen leggen we vast in een Postman collectie (https://www.getpostman.com). Postman is een tool waarmee je API ‘s eenvoudig kan bevragen en (geautomatiseerd) kan testen, inclusief het vastleggen van test cases met requests en assertions op de responses. Met Newman -de command line variant van Postman- draaien we de functionele testen tegen het Kadaster Dataplatform.
Uitdaging
Elke ontwikkelaar begrijpt dat het niet alleen leuk, maar ook pure noodzaak is deze functionele testen te automatiseren om de werking van de applicatie na elke wijziging te kunnen blijven garanderen. Dit is tenslotte één van de pijlers van Continuous Delivery.
De initiële behoefte was daarom de functionele testen te integreren in onze Jenkins delivery pipeline -gebruikmakend van één centrale en bijgewerkte instantie van het Kadaster Dataplatform. Maar… daarbij hanteren we bij het Kadaster Dataplatform het Git feature branch workflow model waarbij elke branch zijn eigen instantie van de Jenkins delivery pipeline kent -Het Git feature branch workflow model houdt in dat voor elke feature een branch van de master branch wordt afgesplitst. Na afronding van de feature wordt de feature branch samengevoegd met de master branch en opgeruimd (https://www.atlassian.com/git/tutorials/comparing-workflows#feature-branch-workflow)- Er kunnen dus meerdere instanties van de delivery pipeline parallel draaien op verschillende branches (feature èn master branches) (afbeelding 2).
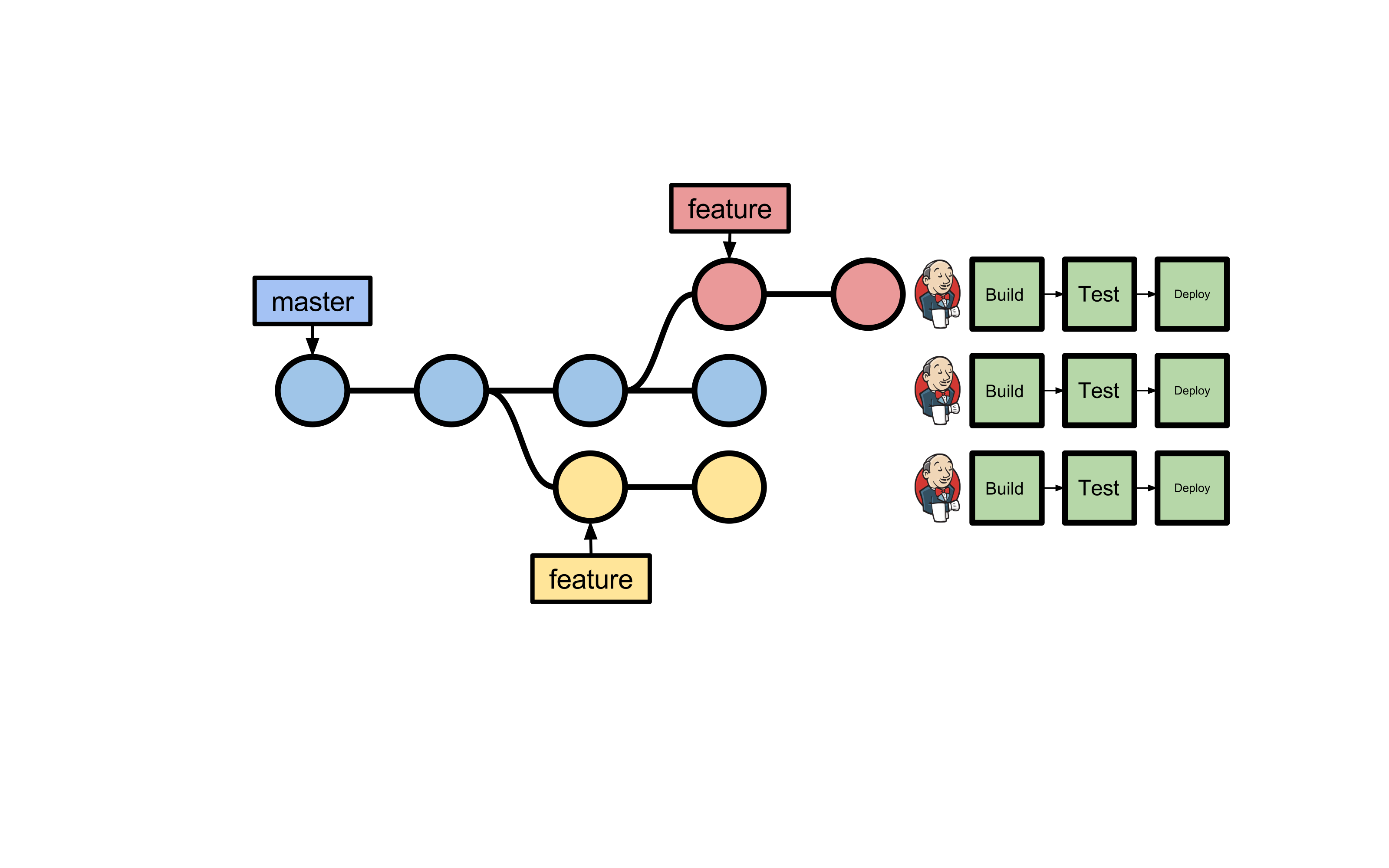
Afbeelding 2
Eén instantie van het Kadaster Dataplatform was daarom niet meer voldoende. De originele behoefte kon daarom worden uitgebreid tot de volgende uitdaging: hoe kunnen we de functionele testen zodanig integreren in onze Jenkins delivery pipeline dat we per Git branch parallel en in isolatie het platform functioneel kunnen testen?
Docker Compose
Omdat het Kadaster Dataplatform volledig is opgebouwd uit Docker containers was de oplossingsrichting tamelijk voor de hand liggend, namelijk: Docker Compose.
Volgens Docker is “docker-compose a tool for defining and running multi-container Docker applications” (https://docs.docker.com/compose/). Vrij vertaald behandel je met Docker Compose een multi-container Docker applicatie (bijvoorbeeld het Kadaster Dataplatform) als één geheel.
Docker Compose bouwt een verzameling Docker containers als één geheel, deployed de containers als één geheel en ruimt de containers als één geheel op. Essentieel hierin is dat Compose de applicatie in isolatie draait, inclusief eigen netwerk en data volumes. Verschillende instanties van Docker Compose applicaties zitten elkaar dus niet in de weg (!) Compose biedt hiermee een oplossing voor onze uitdaging: met Docker Compose kunnen we per Git branch parallel en in isolatie het Kadaster Dataplatform opspinnen en vervolgens de functionele testen met Newman uitvoeren. Met Compose hebben we de mogelijkheid de volledige applicatie life cycle te testen, inclusief het bouwen, deployen en configureren van de applicatie. Waarmee Continuous Delivery binnen handbereik komt.
Een Docker Compose applicatie definieer je met een Compose YAML bestand. Hierin leg je vast uit welke containers de Docker Compose applicatie bestaat:
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.3
ports:
– “9200:9200”
volumes:
– /var/appdata/elasticsearch:/usr/share/elasticsearch/data
dataplatform_api:
image: kadaster-artifactory:8081/dataplatform_api:develop
ports:
– “8282:8282”
environment:
SPRING_PROFILES_ACTIVE: test
Listing 1
Bovenstaand voorbeeld demonstreert de belangrijkste features van een docker-compose file. De Docker Compose applicatie bestaat in dit voorbeeld uit een tweetal Docker containers ook wel services, namelijk elasticsearch en dataplatform_api. De elasticsearch service is gebaseerd op het Elasticsearch Docker image zoals beschikbaar gesteld door Elastic (https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html).
Graag willen we de elasticsearch container vanaf de Docker host kunnen benaderen. Hiervoor exposen we poort 9200 op de container, en mappen deze poort naar dezelfde poort op de Docker host (host:container).
Daarbij willen we de Elasticsearch data lostrekken van de Elasticsearch container, zodat de data behouden blijft indien de container bijvoorbeeld wordt opgeruimd. Daarom mounten we het /usr/share/elasticsearch/data pad in de elasticsearch container naar het /var/appdata/elasticsearch pad op de Docker host (host:container).
De dataplatform_api service gebruikt de laatste stand van zaken van het dataplatform_api image zoals deze in de Kadaster Artifactory te vinden is. Naast de poort mapping definieert de service een omgevingsvariabele getiteld SPRING_PROFILES_ACTIVE met de waarde test.
Met het Docker Compose file kunnen we dus het Kadaster Dataplatform definiëren, om daarna de functionele testen met Newman uit te voeren. De volgende stap bestaat uit het integreren van Compose met de Jenkins delivery pipeline.
Integratie met Jenkins
Om Docker Compose met Jenkins te integreren roepen we effectief een shell script aan vanuit de Jenkinsfile. Dit script bestaat primair uit de volgende stappen:
- export COMPOSE_PROJECT_NAME
- docker-compose pull
- docker-compose up
- docker-compose port
- wait for docker-compose app to be ready
- configure app
- newman run
- docker-compose down
Listing 2
De stappen in listing 2 zien er relatief eenvoudig uit. Helaas is dit een vereenvoudigde weergave van de werkelijkheid 🙂 Wat volgt is een beschrijving van elke stap inclusief de uitdagingen waar we tegenaan zijn gelopen, en hoe we deze hebben aangepakt.
COMPOSE_PROJECT_NAME
Docker Compose kent een Compose applicatie een naam toe, de zogenaamde Compose project name. Dit is de naam die de verzameling containers als één geheel identificeert. Alle containers, het Docker netwerk en de data volumes worden geprefixed met de Compose project name. Standaard is de project name gelijk aan de naam van de huidige directory van waaruit we docker-compose draaien. Willen we parallel meerdere instanties van de Docker Compose applicatie draaien, dan is de standaard naam niet meer afdoende. Een tweede Compose applicatie voor een andere (feature) branch zal tenslotte dezelfde Compose project name toegekend krijgen waarna er een name clash optreedt.
Daarom overschrijven we in stap 1 de standaard Compose project name door de huidige Git branch er aan toe te voegen:
export COMPOSE_PROJECT_NAME=${COMPOSE_PROJECT_NAME}_${BRANCH_NAME}
COMPOSE_PROJECT_NAME is een omgevingsvariabele die door Docker wordt gehonoreerd, BRANCH_NAME wordt ter beschikking gesteld door de Jenkins Pipeline Multibranch Plugin en geeft de huidige Git branch terug.
Stap 2 bestaat uit het binnentrekken van de laatste stand van zaken van de Docker images waaruit de Docker Compose applicatie bestaat met het docker-compose pull commando. Dit kunnen images in eigen ontwikkeling zijn (bijvoorbeeld uit Artifactory) of images van derden (denk aan Elasticsearch). We willen tenslotte de functionele testen draaien op de actuele stand van de Docker images.
Stap 3 omvat het opspinnen van de Compose applicatie, oftewel het starten van de verschillende Docker containers met docker-compose up.
Dynamic port bindings
Een aantal Docker containers is op de Docker host bereikbaar op een voorgedefinieerde poort. Elasticsearch is bijvoorbeeld te benaderen op poort 9200 en Kibana op poort 5601. Zie de eerdere listing 1 voor het voorbeeld voor Elasticsearch.
Willen we parallel meerdere instanties van de Docker Compose applicatie draaien, dan kunnen we niet meer werken met voorgedefinieerde poorten. Een tweede Compose applicatie voor een andere (feature) branch zal tenslotte dezelfde poort willen claimen waarna er een poort clash optreedt.
Daarom binden we de blootgestelde poorten niet meer aan vaste poortnummers, maar laten we dit aan Docker over met dynamic poort binding. We laten aan Docker over op welke poort de container op de Docker host bereikbaar is, effectief door de host poort weg te laten:
version: “2”
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.3
ports:
– “9200”
Willen we daarna vanaf de Docker host een health check doen, dan moeten we wel weten op welke poort we deze check moeten uitvoeren. In stap 4 vragen we dit op met het docker-compose port commando:
docker-compose port <container> <port>
…bijvoorbeeld:
docker-compose port elasticsearch 9200
Hiermee vragen we Docker Compose op welke poort elasticsearch:9200 vanaf de Docker host bereikbaar is. “elasticsearch” is de naam van de service zoals deze in de docker-compose file is gedefinieerd, “9200” is het nummer van de poort welke we hebben blootgesteld.
Het resultaat van dit commando zou er als volgt uit kunnen zien:
0.0.0.0:32769
…Elasticsearch is in dit geval vanaf de Docker host bereikbaar op poort 32769.
Health checks
Omdat een gestartte container niet direct betekent dat de container ook gelijk beschikbaar is om verzoeken af te handelen, moet in stap 5 gewacht worden op een aantal containers. De Elasticsearch Docker container zal bijvoorbeeld na enkele seconden aangeven dat deze “Up” is (met het docker ps commando), maar dit betekent niet dat Elasticsearch ook werkelijk klaar is om bevraagd te worden. Dit kan mogelijk nog enkele tientallen seconden duren, afhankelijk van de beschikbare (virtuele) hardware, de grootte van het Elasticsearch cluster en de hoeveelheid data.
Door gebruik te maken van health checks, kunnen we wachten op de Docker containers totdat deze klaar zijn om verzoeken af te handelen. De status van Elasticsearch kan je bijvoorbeeld met het volgende curl commando opvragen:
curl localhost:9200/_cluster/health
…bijvoorbeeld:
{
“cluster_name”:”kadaster-dataplatform”,
“status”:”green”,
“timed_out”:false,
“number_of_nodes”:3,
[ … ]
“active_shards_percent_as_number”:100.0
}
Voor onze eigen spring-boot applicaties gebruiken we Spring Boot Actuator (https://docs.spring.io/spring-boot/docs/current/reference/html/production-ready.html). Met Spring Boot Actuator kan je zogenaamde “production ready features” toevoegen aan je spring-boot applicatie, zoals /info en /metrics endpoints en een /health check. Het enige wat je hiervoor hoeft te doen is het toevoegen van de spring-boot-actuator “Starter” als dependency.
Na de health checks wordt in stap 6 de applicatie geconfigureerd, bijvoorbeeld met omgeving specifieke zaken zoals security of het inladen van data. Stap 7 bestaat uit het uitvoeren van de functionele testen met Newman, waarna tenslotte in stap 8 de Docker Compose applicatie wordt opgeruimd. Dat wil zeggen: inclusief netwerk en inclusief data (volumes).
Continuous Delivery Simplified
Met Docker en Docker Compose hebben we bereikt dat bij elke change op elke (feature) branch geautomatiseerd het volledige Kadaster Dataplatform van de grond af aan wordt opgebouwd, uitgerold en geconfigureerd. Om vervolgens de functionele testen te draaien en het platform weer op te ruimen. En dat parallel, in isolatie, binnen enkele minuten en op één enkele Docker machine.
Essentieel hierin is dat niet alleen de functionele testen worden gedraaid, maar ook dat bij elke change het Dataplatform from scratch wordt uitgerold en geconfigureerd, waarmee ook dit belangrijke deel van de applicatie life cycle continue wordt geverifieerd. Continuous Delivery wordt hiermee sterk vereenvoudigd. Dankzij Docker en Docker Compose.