 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Ready to transition to the future industry standard for API building?
In today’s applications you really want to be able to rapidly iterate over your designs and experiment with different features. If every small front-end change requires an API tweak or an extra API must be built for every small piece of information, you will not be able to iterate quickly and deliver features that the current agile market expects.
Auteur: Girum
GraphQL addresses the shortcoming of the RESTful API lifecycle by exposing only a single API endpoint and allowing clients to query through an existing HTTP post for the data that they exactly want. The specification was first drafted by Facebook in 2012 while trying to solve a specific problem they encountered when migrating their HTML5 based mobile app to a native iOS one. The news feed API in particular made things extremely complicated.
The specification designed to solve a specific problem for a Facebook application turns out to be the silver bullet for many API design problems. GraphQL gives an answer for modern application requirements: efficiency for data fetching, handling various frontend frameworks and platforms, and quick iteration where businesses expect a rapid feature delivery (feature rollout and deprecation).
Back in the day, when applications were relatively simple and requirement changes came once in a while, REST was the popular choice for many applications to expose data from a server. The last decade things have changed dramatically. Application features have become relatively complicated and require more in terms of data efficiency. Furthermore, previous luxuries such as continuous deployment have become a standard too. In order to meet growing demand and adapt to the rapidly changing API landscape, we needed to rethink how we build APIs and GraphQL seems to be giving the answers. It might just be the future industry standard.
What is GraphQL?
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL is a new API standard that provides a more efficient, powerful and flexible alternative to REST. It is a specification built around HTTP for how you send and receive resources to and from a server. It provides a complete and understandable description of the data in your API and allows clients to ask for what they need exactly. Nothing more, nothing less.
The specification is relatively new and was officially announced at the React Europe conference in 2015. However, it was used internally by Facebook three years prior. After it was made public and open-sourced by Facebook. It gained adoption with elite companies and communities around the world where it is now governed and maintained.
The GraphQL specification can be implemented in any server-side language and client-side technologies. In fact, it is also possible to send the query string via POST without any GraphQL client library.
Use Case
For this particular article, I set up a small Node.js project with a mongoDB and expose a bicycle BOM via a single GraphQL API. A BOM or bill of materials or product structure is a list of the raw materials, sub-assemblies, intermediate assemblies, sub-components, parts and product.
A common BOM data structure in itself is graph data where a material can have a list of children and parents. In my opinion, it is a perfect scenario to demonstrate elegant graph traversal queries with a GraphQL API.
With one of the queries we can, for example, search for an item and locate in which sub-assembly of a bicycle it is found.
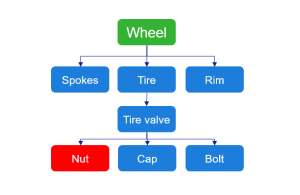
You can clone or download the sample project repo from this link: https://github.com/girumasfaw/cider
The Type System
GraphQL has its own type system to define the schema of an API. The syntax is called Schema Definition Language (SDL). Once defined, it can act as an API contract between the front-end and back-end developers. The two teams can work independently with almost no communication.
For instance, to define a simple type called Item we can do the following (Listing 1).
Type ItemType {
itemNumber: String!
Description: String!
}
Listing 1
Creating a relationship between types is also possible. In the use case API, an item can be linked to its parents and children. In the case of a BOM, a child or parent type is also an Item type with quantities, here we can introduce a new type called relationType (Listing 2).
Type RelationType {
Quantity: String
Item: ItemType
}
Listing 2

Querying data efficiently
You can easily use REST APIs to expose the bicycle BOM data. These endpoints can provide a fixed information structure, meaning you need one for each custom query that the client requests or you can have a small number of APIs overloaded with unnecessary information.

If the front-end requires specific information about an item or if you want to add or remove information from the response, you should definitely introduce a new endpoint that fulfils the demand. Even for a simpler application, if there is a need for a custom information structure, the API list can grow enormously which makes maintaining and iterating a pain.
In most cases, you will either have some REST APIs that respond with a big chunk of information and let the client over-fetch unnecessary data. Or you will have a number of APIs that respond with small information and let the client make round trip(under-fetch) to get all the necessary information. With the later approach the client will face the N+1 problem. Which means the client is required to call the server N+1 times to fetch the resource. By using REST as your API design choice, facing one of these two problem is inevitable.
With GraphQL it is a whole different story, as there is no list of APIs to tweak and maintain. The data is exposed with only one endpoint and the response structure is as flexible as the client requested.
Ask for what you want
GraphQL allows the clients to ask for exactly what they need and get just that – nothing more, nothing less. Suppose an item has more than 50 fields and the front-end view might be interested in two of them specifically.
Then you can only ask for these two fields, see figure 4 and 5.


It has a huge advantage in keeping you from exposing an additional endpoint just for that one purpose and it can also significantly improve performance, especially if the client’s bandwidth is scarce.
Over- and under-fetching is solved
Fetching too much data or not having enough data from an endpoint call can cause a performance issue, as you are either using more bandwidth or making more HTTP requests than you should. Often, if your application requirement does not change, these issues are not even considered because you would have a specific endpoint that returns the data that the view in your application demands.
These problems often occur when you scale and iterate your application. The data you use for your view changes often, and the cost of maintaining an individual endpoint with just the right data for each view becomes overwhelming.
So, you end up with a compromise between not having too many endpoints and having the endpoints fit each application view needs best. This will lead to over-fetching in some cases, and under-fetching in some others.
GraphQL fixes this problem because it allows you to request the data you want from the server. You specify what you need and you will get this data, and only this data, in one trip to the server.
Parameterized Query
GraphQL fields can have zero or more arguments if it is defined in the schema. For example, you can pass an Item ID argument to the itemByNumber query parameter below and get a result for a specific item. See figure 6 and 7.


As it is specified by the specification, all GraphQL requests return a dictionary with a key of data. Yet, you can use aliases to return objects with a different name than their field name, see figure 8.

Mutations
In addition to querying, you can also change the data with the so-called mutations. Basically, creating, updating and deleting existing data. The syntax for mutation looks similar to querying. In our example API, you do this by calling the root field createItem and passing arguments. The same as query, you can also specify a payload for a mutation in which you can fetch different properties of the newly created Item. For example, when a new Item is created, you could directly ask for the id in the payload of the mutation, as that is information that was not available on the client beforehand, see figure 9 and 10.


Being able to also query information when sending mutations can be an immensely powerful tool that allows you to retrieve new information from the server in a single roundtrip!
Realtime data with subscription
Today’s applications require a real-time connection to the server in order to get a notification as soon as an event occurs at the server, so that they can update the view.
GraphQL offers the concept of subscriptions. Subscriptions are a way of pushing data from the server to the clients in real time. As defined by the GraphQL specification: “A subscription is a long-lived request that fetches data in response to source events”.
The subscription below specifies itemUpdated as a source event. Whenever that event occurs, the server pushes the updated children list to the client. You can even change the item response key with an alias child, see figure 11.

After a client sends this subscription to a server, a connection is established between them. When a new mutation is performed that updates the specified item, the server sends the updated information to the client.
Open source tools
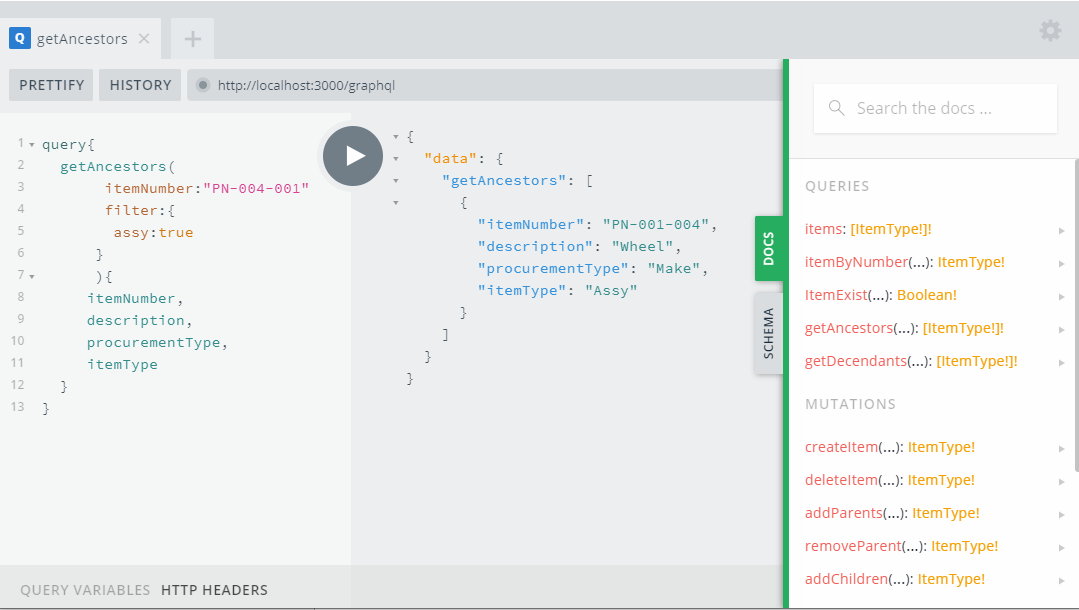
You can find a comprehensive list of opensource GraphQL projects and tools in this link: https://github.com/chentsulin/awesome-graphql. GraphQL allows clients to ask a server for information about its schema and what queries it supports. GraphQL calls this introspection. Many tools available in the GraphQL ecosystem use the introspection system to provide amazing features. Think of documentation browsers, autocomplete, code generation, anything is possible. One of the most useful tools you need to build and use GraphQL APIs makes heavy use of introspection. It is called GraphiQL, see figure 12.
Conclusion
GraphQL is an exciting recent technology, that matured in a noticeably short period of time and powers major data intensive applications such as Facebook, Github and Twitter to name a few. By implementing GraphQL in both the front-end and the back-end of your application, you can easily overcome the shortcoming of REST APIs.
By incorporating GraphQL in your application, front-enders will be equipped with superpowers they never had before: access to a flexible API that can meet the need for views with neither too much or not enough data. Backend developers can focus on describing the data available, rather than deploying and optimizing specific endpoints for each requirement change from the front-end.
Whether your project is ready to implement GraphQL or not, it is worth a try. As the creator says: “Think in graphs instead of APIs”. Since graphs resemble our natural mental model, we can easily model many real-world problems. With GraphQL you model your business domain as a graph by defining a schema; within your schema, you define different types of nodes and how they are connected / related to each other.
References
https://docs.nestjs.com/graphql
https://github.com/prisma-labs/graphql-playground
https://en.wikipedia.org/wiki/Bill_of_materials
BIOGRAFIE
 Girum is a software engineer who likes to keep himself up to date with the latest JavaScript trends and solves complex problems with it.
Girum is a software engineer who likes to keep himself up to date with the latest JavaScript trends and solves complex problems with it.