 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Een data integratie platform met Spring Boot
In dit artikel behandelen we Spring cloud dataflow. Na te behandelen wat het is, kijken we naar de architectuur en sluiten we af met mogelijke use cases om Spring cloud dataflow in te zetten.
Spring cloud dataflow, hierna genoemd dataflow, is een streaming en batch platform dat gericht is om te deployen op Cloud Foundry, Kubernetes of lokaal op een eigen infrastructuur. Kort gezegd is het een microservice chassis waar je jouw eigen microservices kan deployen waarbij Dataflow zorgt voor de onderlinge connecties tussen jouw services zodat je dit niet zelf handmatig of in de afzonderlijke services hoeft te configureren.
Dataflow gaat er vanuit dat je gebruikmaakt van Spring boot en Spring Cloud libraries. De connectie tussen de verschillende services worden door middel van messaging gemaakt. Standard heb je de keuze uit RabbitMQ of Kafka. Dit staat niet vast en je kunt door middel van configuratie ook andere implementaties gebruiken. Dataflow verwacht dat voor elke service die je implementeert de standard Spring cloud channels gebruikt genaamd “input” en “output”. De reden hiervoor is dat daardoor je flexibel pipelines kunt opzetten. Een goed vergelijk zou zijn met Linux utilities, die hebben ook een standard input en output zodat je verschillende tools aan elkaar kunt koppelen door middel van het pipe commando.
In dit artikel ga ik niet diep in op Streams en Task services, die verdienen hun eigen artikel. Wil je meer weten kun je de uitstekende documentatie en tutorials daarbinnen uitvoeren. Dataflow heeft zijn eigen microsite te vinden op https://dataflow.spring.io.
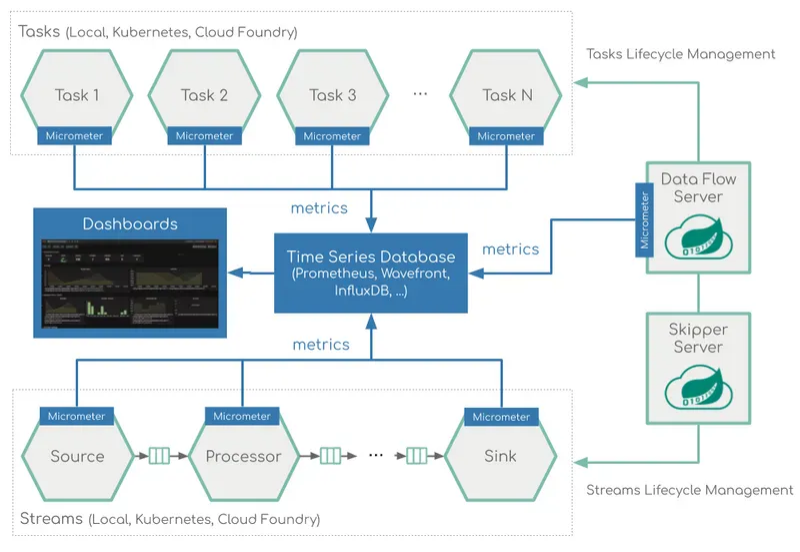
De Dataflow architectuur
Het dataflow platform bestaat uit de Dataflow server, een relationele database en Skipper. Op afbeelding 1 zie je daar een schematische weergave van. Voor monitoring wordt Micrometer gebruikt waarbij je de metrics naar verschillende databases kan sturen zoals Prometheus, Wavefront en influxDb.
De Dataflow server te samen met de database is de kern van de architectuur. Je kunt de Dataflow server het beste vergelijken met een Service registry in combinatie met een Pipeline systeem waarbij je de verschillende services aan elkaar kunt koppelen. Dit kun je doormiddel van de web GUI of door gebruik te maken van een DSL. Je kunt services deployen en diverse parameters configureren zoals aantal instanties, memory settings en data partitionering. Daarnaast biedt de Dataflow server ook auditing functionaliteit aan van het deployen, deleten en opstarten van jobs en monitoring mogelijkheden. Het daadwerkelijk deployen delegeert de Dataflow server aan de Skipper server.
Skipper kun je beste zien als deployment bridge tussen de Dataflow server en de omgeving waar je de architectuur wilt deployen. Dit zorgt er voor dat er verschillende implementatie targets toegevoegd kunnen worden zonder de dataflow implementatie hard te koppelen aan runtime environments. Op dit moment ondersteund de Skipper server locale, Kubernetes en Cloud Foundry omgevingen. Skipper stelt je in staat Spring boot applicaties te doorzoeken in repositories, installeren, upgraden en terugdraaien van deployments. Skipper houdt ook de deployment historie bij. Zowel de Dataflow server en Skipper zijn zowel via een Web GUI en een API te benaderen, daarnaast is de Dataflow server ook door middel van een CLI te benaderen. Beiden maken gebruik van zowel Basic authenticatie als OAuth 2.0 en wordt LDAP ondersteund.
Dataflow applicatie concepten
Spring cloud dataflow maakt een globaal onderscheid tussen twee categorieën services, Long lived en short lived. Long lived applicaties zijn Stream gedreven, hiervoor gebruik je ook de Spring Cloud Stream library. Deze hebben de eigenschap dat deze continu draaien. Short lived applicatie draaien een vaste tijd. Deze applicaties hebben de eigenschap dat deze een eindige hoeveelheid data verwerken en daarna stoppen. Daarnaast kunnen Short lived applicaties gescheduled worden. Denk aan batch georiënteerde processen.
Long lived applicaties hierna Stream services genoemd komen in twee varianten. De eerste variant heeft een input kanaal en/of een output kanaal hebben. De andere variant heeft meerdere inputs en outputs. Voor de laatste variant moet je wel custom bindings creëren om deze te kunnen gebruiken binnen Dataflow. Stream services bouw je door middel of van de Spring Cloud stream API, via de Web GUI of de Dataflow CLI. Stream gebruikt het concept van Source, Processors en Sinks. Source services produceren messages, Sinks consumeren messages en Processors zijn zowel Source als Sink.

Op afbeelding 2 zie je een voorbeeld van een pipeline definitie uit de documentatie waarbij gebruik gemaakt wordt van de Dataflow CLI.
Interessant is dat Spring Dataflow een zestigtal Stream services heeft die je kunt gebruiken als basis. In dit voorbeeld wordt een stream pipeline gecreëerd met de http en log service. Door middel van het pipe teken worden beide services aan elkaar gekoppeld. In deze simpele Stream pipeline wordt iedere keer dat de endpoint aangeroepen wordt de request log doorgestuurd naar de log service. Daarna kun je in Grafana de log terugvinden. Op afbeelding 3 zie je de runtime architectuur van een pipeline samengesteld uit en http en een jdbc stream ter illustratie.

Batch services bouw je door middel van het Spring Cloud Task library. Met Spring Cloud Task Library kun je kort levende services bouwen die de start, eindtijd en exit code loggen. Wanneer je al met Spring Batch heb gewerkt, zal Spring Cloud Task je hieraan laten denken, er zijn gelijkenissen maar Spring Batch heeft veel meer mogelijkheden dan Spring Cloud Task. Dataflow geef je de mogelijkheid om Composed Tasks te definiëren. Composed Tasks zijn een verzameling Task die in een bepaalde volgorde gedraaid worden, denk hierbij conceptueel aan een Job. Op afbeelding 4 zie je een voorbeeld van een Task applicatie die facturatie gegevens ophaalt en verwerkt in een database.
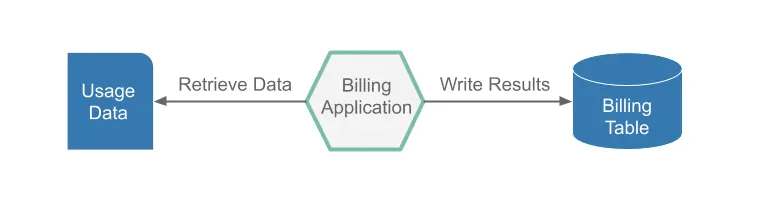
Dataflow biedt je de mogelijkheid om Task applicaties op meerdere runtime platforms te deployen. Daarnaast kun je de Tasks ad-hoc starten of schedulen. Door gebruik te maken van Spring Batch kun je gefaalde jobs herstarten via Dataflow vanaf het gefaalde punt als je de Batch zo geschreven heb dat deze dat ook ondersteunt.
Dataflow use cases
Spring zelf raadt Dataflow aan voor data integratie vraagstukken. Wat het platform interessant maakt is dat je pipelines kunt declareren voor de vaste stromen maar ook tijdelijke pipelines kunt creëren om bijvoorbeeld een datamigratie of eenmalige conversie te maken van bestaande services.
Use cases om dit platform in te zetten zouden bijvoorbeeld om een data lake te voeden. Daar zie je vaak vele verschillende datastromen die sterk afwijken van elkaar waarbij de koppelingen ook nog eens sterk wijzigen. Een andere interessante use case zou een groot (legacy) batch georiënteerd systeem in dataflow onder te brengen. Dit zou als eerste de onderhoudbaarheid en beheersbaarheid vergroten. Daarnaast zou je wellicht zelfs gecontroleerd stappen kunnen maken om van batch georiënteerd naar streaming georiënteerde manier van werken te implementeren.
Hoewel je op het Dataflow platform ook applicaties kunt draaien die niet op Spring gebaseerd zijn, lijkt dit wel veel boilerplate op te leveren. Om optimaal gebruik te maken van Dataflow is het goed om bekend te zijn of worden met Spring Cloud Stream, Spring cloud Task en Spring Batch. Ook interessant om te noteren zijn dat de services die je ontwikkelt niet vast aan Dataflow zitten, met andere woorden kun je deze services zelfstandig draaien en op eigen omgevingen deployen.
Wil je spelen met Dataflow kun je dit lokaal installeren of zoals ik gedaan heb op een Minikube instantie installeren. De documentatie biedt verschillende installatie mogelijkheden die je hier stap voor stap in begeleiden. Ik heb eerst dit via Helm gedaan, dit nam veel tijd in beslag maar zou kunnen door mijn beperkte kennis van Helm daarna heb ik de kubectl gebruikt, dat ging snel maar waren wel veel handmatige stappen.
Spring heeft een minisite voor Dataflow, daar vind je de documentatie voor het installeren, tutorials en de gebruikers documentatie.
Auteur Bio: Ben Ooms is een gepassioneerde Java software engineer die graag bezig is met de nieuwste ontwikkelingen.