 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Author: Artur Costa
Original post on Foojay: Read More
Table of Contents
The scenario
Imagine we are responsible for managing the MongoDB cluster that supports our country’s national financial payment system, similar to Pix in Brazil. Our application was designed to be read-heavy, with one write operation for every 20 read operations.
With Black Friday approaching, a critical period for our national financial payment system, we have been entrusted with the crucial task of creating a scaling plan for our cluster to handle the increased demand during this shopping spree. Given that our system is read-heavy, we are exploring ways to enhance the read performance and capacity of our cluster.
We’re in charge of the national financial payment system that powers a staggering 60% of all transactions across the nation. That’s why ensuring the highest availability of this MongoDB cluster is absolutely critical—it’s the backbone of our economy!
A solution from AI Models
As a database administrator or database developer in 2025, our first step when searching for solutions is to consult AI. These AI models, including GPT-5, Grok Code Fast 1, Claude Sonnet 4, and Gemini 2.5 Pro, are advanced tools that can provide insights and recommendations based on the specific query we ask. I asked the question, “How can I increase read performance and capacity in a MongoDB replica set cluster?” to these AI models.
A standard recommendation across all responses was to distribute read operations to secondary nodes using the readPreference setting to enhance performance and increase the number of secondary nodes to boost read capacity.
An interesting observation is that nearly all AI models correctly warned that reading from secondary nodes could yield stale information, which means the data might not be the most up-to-date, as the replication of write operations between nodes requires some time.
The pitfall of scaling capacity by reading from secondary nodes
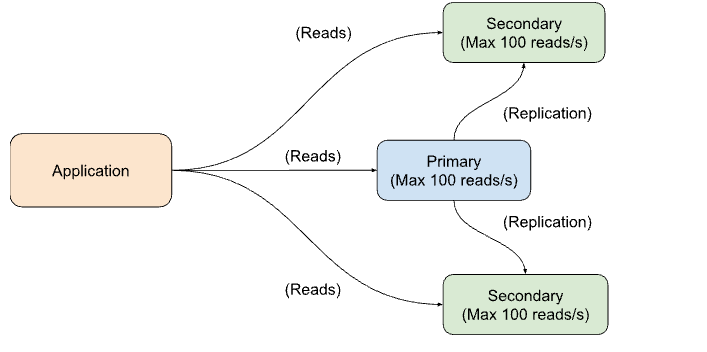
Let’s imagine we have a replica set cluster consisting of three nodes: one primary node and two secondaries. Each node can handle up to 100 read operations per second. If we distribute the read operations equally among the nodes, the entire replica set cluster should be able to accommodate a total of 300 read operations per second.
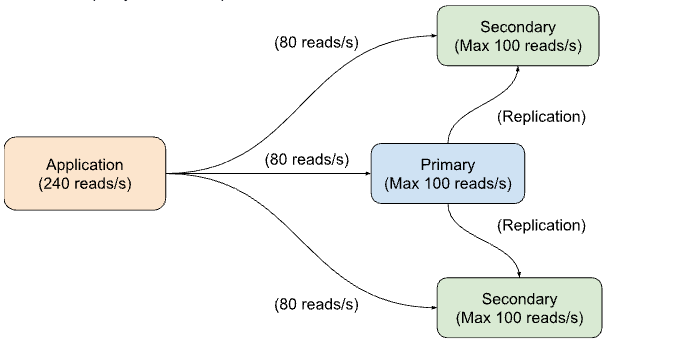
Our application requires 240 read operations per second. Since we have configured it to balance the operations across the replica set nodes, each node will handle 80 read operations per second, which is below its capacity of 100 reads per second.
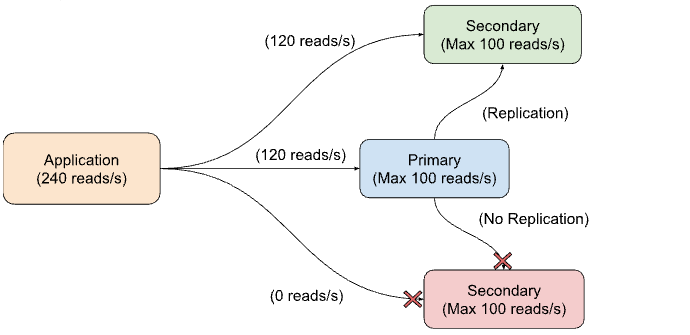
However, a potential risk lurks in the shadows. Imagine a network outage in one of the availability zones where one of our replica set nodes is deployed, causing this primary or secondary node to go down. Now, our application is still requesting its 240 read operations per second, but with only two nodes remaining, each node needs to process 120 read operations per second.
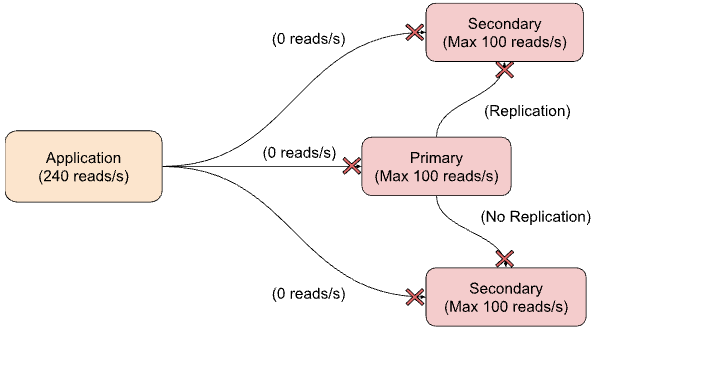
Since each node can only handle 100 read operations per second, this overloads their hardware, which may lead to further failures. As a result, the remaining nodes may go down, taking down the entire MongoDB cluster along with the application.
Increasing read capacity vs increasing read performance
Let’s first clarify the difference between read capacity and read performance in a MongoDB cluster:
- Read capacity: How many read operations the cluster can manage without overloading its hardware or significantly increasing the time required to complete these operations
- Read performance: How quickly a read operation can be fulfilled by the cluster
As discussed previously, utilizing secondary nodes to enhance the cluster’s read capacity may inadvertently reduce its availability. This availability reduction occurs because if one node fails, the remaining nodes could become overloaded with read requests.
Therefore, when high availability is crucial for your application, reading from secondary nodes should be limited to improve performance. Two ways of doing that are:
- Proximity: Locating the secondary node closer to the application reduces the latency of requests and responses between them.
- Caching: Consistently executing the same queries on the same node allows its cache to retain the necessary data, leading to faster query fulfillment.
Properly increasing read capacity
To safely and reliably increase read capacity without sacrificing availability, the best approach is to scale your cluster—either vertically (scaling up) or horizontally (scaling out).
Vertical scaling (scale up)
This method involves increasing the resources of existing nodes, such as CPU, RAM, storage, and IOPS.
- Advantages:
- Operational simplicity: No changes are needed for data distribution or query routing.
- Minimal application change: Connection strings and query patterns typically remain the same.
- Immediate performance improvement: It’s particularly effective for workloads that are limited by CPU or memory.
- Disadvantages:
- Upper limits: Eventually, you will reach the maximum instance size available; a single machine’s resources can cap throughput.
- Non-linear performance growth: The performance of your application usually doesn’t grow linearly with the instance size, meaning that doubling your resources might not double your throughput.
- Single-node bottlenecks: Hot documents or collections and heavy aggregation can still face contention for a primary node’s resources.
- [MongoDB EA only] Obtain and provision additional resources: While MongoDB Atlas offers simple methods for vertical scaling, on-premises deployments often face limitations due to resource availability.
Horizontal scaling (scale out via sharding)
This approach distributes data and workload across multiple shards by partitioning the data.
- Advantages:
- Near-linear throughput growth: Adding shards can increase capacity for both reads and writes, in addition to total storage.
- Hotspot mitigation: Proper shard keys can help evenly spread the load to avoid bottlenecks on individual nodes.
- Geographic flexibility: Zone sharding keeps data close to users and meets data residency requirements.
- Disadvantages:
- Design complexity: Selecting the right shard key is crucial; poorly chosen shard keys can lead to imbalances or inefficient scatter-gather queries.
- Operational overhead: Tasks such as chunk balancing, resharding, and managing cross-shard queries or transactions can add complexity.
- Query pattern considerations: To maximize targeted reads and avoid fan-out, applications may need to include the shard key in their queries.
- [MongoDB EA only] Obtain and provision additional resources: While MongoDB Atlas offers simple methods for horizontal scaling, on-premises deployments often face limitations due to resource availability.
For more information on scaling in MongoDB, refer to the articles “A Guide to Horizontal vs Vertical Scaling” and “Database Scaling,” or check the official documentation on scaling strategies.
Maybe other ways around it?
Some readers who are more knowledgeable about MongoDB cluster topology and node types may think that, at least in MongoDB Atlas, we could have increased our cluster’s read capacity by utilizing read-only or analytical nodes. As Master Yoda would say, “Much to learn you still have, my young padawan.” First, let’s understand what these nodes are and their purpose, and then we can assess whether they fit our needs.
Read-only node
In reviewing the official MongoDB documentation for Atlas read-only nodes, I’ve identified two key points that are particularly relevant to our case:
- “Use read-only nodes to optimize local reads in the nodes’ respective service areas.”
- “Read-only nodes don’t provide high availability because they don’t participate in elections.”
The first point indicates that read-only nodes can enhance performance by being located closer to the application, thereby reducing read latency. However, since our goal is to increase read capacity, this solution is not ideal.
The second point emphasizes that read-only nodes do not contribute to high availability, which is a critical requirement for our application. Therefore, this aspect does not provide any advantage for us.
Analytics node
In reviewing the official MongoDB documentation for Atlas analytics nodes, we can find very similar relevant points of attention to the read-only case:
- “Use analytics nodes to isolate queries which you do not wish to contend with your operational workload.”
- “Read-only nodes don’t provide high availability because they don’t participate in elections.”
The second point is the same as in the read-only case, so there’s no need for further discussion on it. The first point implies that the analytics node will handle analytical queries, which could negatively impact the performance of everyday queries in your application. Therefore, this does not contribute to increasing read capacity.
Conclusion
While distributing read operations across secondary MongoDB nodes to boost capacity might sound appealing, it can inadvertently impact availability—something that’s crucial for systems like our national financial payment network. Such an approach could lead to cascading failures during outages, which we definitely want to avoid!
Instead, focus on scaling strategies. Consider vertical scaling for immediate performance enhancements, or horizontal sharding to ensure consistent throughput and address hotspot concerns. While read-only and analytical nodes offer certain benefits, they don’t fully address the need for high availability and read capacity.
The post The Pitfall of Increasing Read Capacity by Reading From Secondary Nodes in a MongoDB Replica Set appeared first on foojay.