 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Author: Jonathan Vila
Original post on Foojay: Read More
Table of Contents

 The Code Face-off: Filtering a list
The Code Face-off: Filtering a list
 The danger of “Blockers”
The danger of “Blockers”
 For Business Core and Security: Opus 4.5 Thinking
For Business Core and Security: Opus 4.5 Thinking For extreme logic cases: GPT-5.2 High
For extreme logic cases: GPT-5.2 High
The LLM ecosystem
Let’s be honest: when we try a new AI model, the first thing we look at is if the code compiles and does what we asked. But if you have been in the Java world for a while, you know that “working” is just level 1. The real final boss is maintenance and security. 💀
I have been analyzing the latest SonarSource Leaderboard (with fresh data from late 2025/2026 on 4,444 tasks) and there are big surprises.
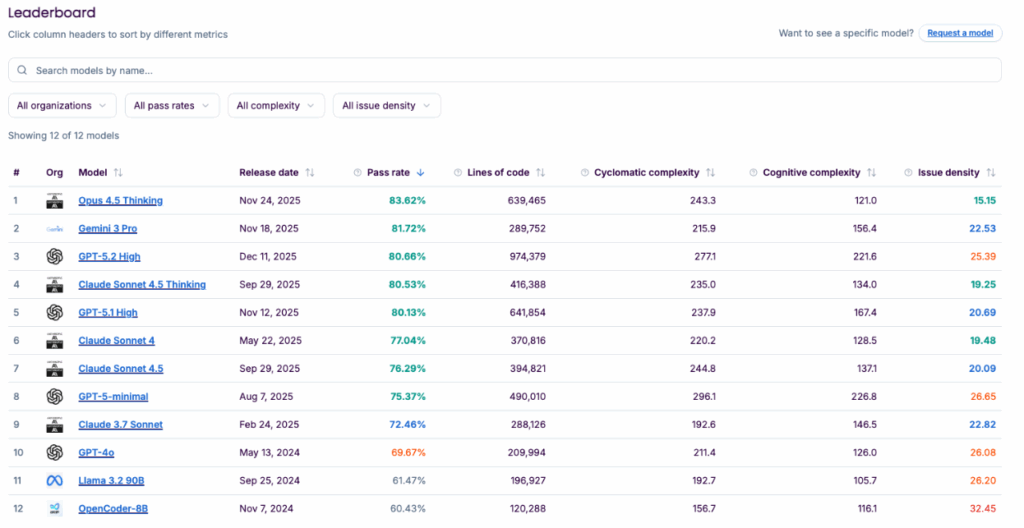
☝️ An important detail: This leaderboard has evolved fast. What started analyzing initially only 5 models has expanded drastically to include the whole new wave of AIs that have flooded the market. Now that we have a much wider range (from the new “Thinking models” to the Gemini family), with 12 models covered, the quality differences between them have become much more evident.
Not all “high-end” models write code that you would want to push to production. Here is what the numbers and the code say, straight up. 👇
1. The “Bloatware” Trap: Precision vs. Verbosity 📉
One of the craziest stats from the leaderboard is the difference in the amount of code that different models write to solve exactly the same problem.
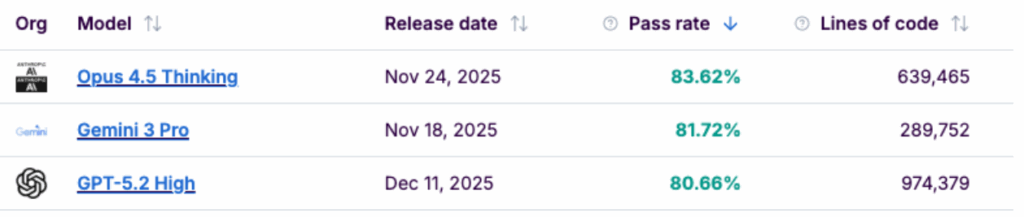
We have two contenders with a very similar success rate (Pass Rate) (~81%), but with opposite approaches:
- Gemini 3 Pro: Solves the problem set with ~289k lines of code.
- GPT-5.2 High: Needs almost 1 million lines (974k LOC) for the same thing. 🤯
Why should you care? Because the verbose model could add unnecessary boilerplate code and avoid using modern Java features.
🆚 The Code Face-off: Filtering a list
Based on the cyclomatic complexity metrics from the report, this is how the code generated by these model profiles would potentially look:
What you could expect from a “Verbose” model (GPT-5.2 High style): They usually add a lot of unnecessary defense, classic loops, and high complexity.
// ❌ Simulated example of a model with high verbosity/complexity
public List<String> filterValidUsers(List<User> users) {
List<String> validNames = new ArrayList<>();
if (users != null) {
for (User u : users) {
if (u != null) {
try {
String name = u.getName();
if (name != null && !name.trim().isEmpty()) {
validNames.add(name);
}
} catch (Exception e) {
// Defensive try-catch inside a loop... bad idea 🤦♂️
continue;
}
}
}
}
return validNames;
}
What an “Efficient” model would tend to generate (Gemini 3 Pro / OpenCoder style): Direct, readable, and using the Streams API correctly.
// ✅ Simulated example of an optimized and concise model
public List<String> filterValidUsers(List<User> users) {
if (users == null) return Collections.emptyList();
return users.stream()
.map(User::getName)
.filter(name -> name != null && !name.isBlank())
.toList(); // Java 16+ style
}
Which one do you prefer to maintain in 6 months? Exactly.
2. Security: A “Bug” is not the same as an “Open Door” 🚨
Here is where things get serious. Many devs assume that if a model is “smarter”, it writes safer code. Spoiler: No.
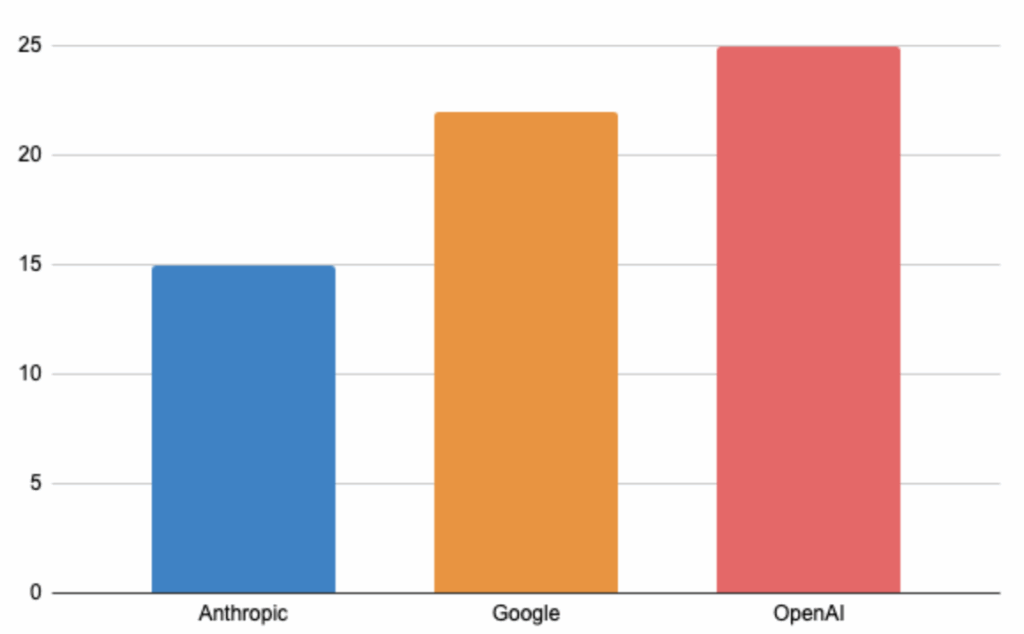
The leaderboard measures Issue Density. Models like Opus 4.5 Thinking have a very low density (15.15), while others like Llama 3.2, GPT 5 and 4o can go over 26 issues/kLOC. But the serious part is not the quantity, it is the criticality.
💀 The danger of “Blockers”
I have seen that new models, when trying to be “flexible”, can reintroduce vulnerabilities that we thought were forgotten.
Example: Database Queries
A model with high issue density could generate code that prioritizes building the String fast rather than security:
// ❌ Critical Security Hotspot (SQL Injection)
// Typical of models that don't "think" (Chain of Thought) before writing
public List<User> search(String username) {
String query = "SELECT * FROM users WHERE name = '" + username + "'";
return entityManager.createNativeQuery(query, User.class).getResultList();
}
While a secure model (like Opus 4.5 Thinking) would tend to use Prepared Statements by default:
// ✅ Secure Code
public List<User> search(String username) {
String query = "SELECT * FROM users WHERE name = :username";
return entityManager.createNativeQuery(query, User.class)
.setParameter("username", username)
.getResultList();
}
Pro Tip: If you use a model with high Issue Density (>25), assume there are vulnerabilities. ALWAYS run a SAST scanner (like SonarQube) before accepting the PR.
Difference in terms of issue density on the main model of each organization:
3. “New” does not guarantee “Better Code” 📉
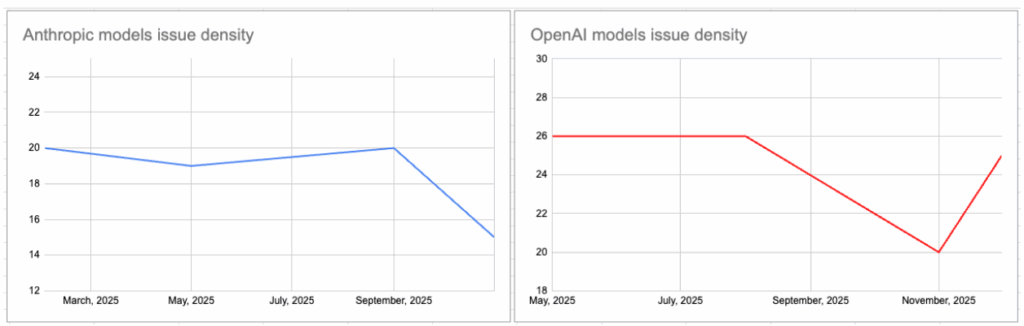
There is a belief that version v5 will always be cleaner than v4. Sonar’s data says: “Not so fast!”.
Look at the regressions in technical quality:
- GPT-4o (May ’24): Issue Density of 26.08.
- GPT-5-minimal (Aug ’25): Issue Density of 26.65.
Sometimes, new models reintroduce basic Code Smells, like generic exception handling, just to “get by” and give you a quick answer.
// 🤢 The classic "Smell" that usually reappears in rushed models
try {
processData();
} catch (Exception e) {
// Catching 'Exception' is lazy and hides real errors
e.printStackTrace();
}
4. The Verdict: Which model should I use for Java? 🏆
Forgetting the hype and looking only at engineering metrics (Pass Rate + Clean Code), here is the guide:
✅ For Business Core and Security: Opus 4.5 Thinking
It is the current king of the leaderboard.
- Pass Rate: 83.62% (The highest).
- Cleanliness: 15.15 Issues/kLOC (The safest).
- Drawback: it’s a slow model, so not appropriate for small coding fixes.
Verdict: Use it where you cannot afford errors, and the task is complex enough. It introduces the least technical debt.
✅ For “Day to Day” and Maintenance: Gemini 3 Pro
The balanced option.
- Efficiency: Very few lines of code (Low Verbosity).
- Quality: Maintains an elite Pass Rate (>81%).
- Verdict: Ideal for generating tests, scripts, or standard features where you want clean and easy-to-read code for your human colleagues.
⚠️ For extreme logic cases: GPT-5.2 High
- Power: Solves very hard problems.
- Cons: Be prepared to refactor a lot of verbose code and clean bad smells.
Final Summary 📝
Don’t let the Pass Rate blind you. Code that works but is full of security holes or has absurd cyclomatic complexity is a time bomb. 💣
Choose tools that respect your time (and your security team’s time). See you in the next commit! 🚀👨💻
The post 🛡️ Dev Guide: How to choose your LLM without ruining your Java code (2026 Edition) appeared first on foojay.