 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
An exciting part of software development is what was unanimously considered good practice at one point in time can be more ambiguous years later. Or even plain wrong. However, you generally need to do it multiple times over time to realize it. Here are my top learnings from my experience in Java projects.
Packaging by layers
When I started my developer career in Java, every project organized their classes by layers – controllers, services and DAOs (repositories). A typical project’s structure would look like this:
ch.frankel
├─ controller
│ ├─ FirstController
│ └─ SecondController
├─ service
│ ├─ FirstService
│ └─ SecondService
└─ dao
├─ FirstDao
└─ SecondDao
This approach has two main disadvantages:
- From a visibility point-of-view, to use classes outside their package, you need to mark them as
public.FirstControllerusesFirstService, hence the latter must bepublic. Because of this, any other class can use it, whereas I want it to be used only for “First”-related classes. - If you want to split the application, you’ll first need to analyze the dependencies to understand the coupling between packages.
To fix these issues, I found that packaging by feature is a much more natural fit:
ch.frankel
├─ first
│ ├─ FirstController
│ ├─ FirstService
│ └─ FirstDao
└─ second
├─ SecondController
├─ SecondService
└─ SecondDao
This way, the controller is public and represents the entry point in the feature. Services and DAOs are an “implementation detail”: they have the package visibility and can only be accessed from inside their package.
As an added benefit, if you need to split your code, you only need to do it by package.
Blindly obey quality tools
I found myself using a quality tool named Hammurapi a long time ago. For the record, it still has an online presence, even if it feels like it hasn’t been updated in ages. Anyway, when I ran the engine on my codebase, the most reported violation was the lack of JavaDocs on public methods. Given that all getters and setters were public, I got many of them.
It was easy to automate adding JavaDocs via a program:
/** Get thefoo. @return Current value offoo*/ public Foo getFoo() { return foo; } /** Set thefoo. @param foo New value offoo*/ public void setFoo(Foo foo) { this.foo = foo; }
It satisfied the side of me that loves green checks. However, there was no added value.
In fact, most quality tools have a pretty low return over investment. It’s not because you used tabs instead of spaces that your project’s quality decreases drastically. Code quality is hard to define, complicated to measure, and doing so in an automated way even more so.
While I’m not saying to avoid quality tools, be careful with metrics they give you. Engineers and managers love metrics, but it can lead your team/organization to places you don’t want to go, even with the best intentions.
Setters
After creating a class, Java developers always generate accessors for it, i.e., getters, and setters.
public class Money {
private final Currency currency;
private BigDecimal amount;
public Currency getCurrency() {
return currency;
}
public BigDecimal getAmount() {
return balance;
}
public void setAmount(BigDecimal amount) {
this.amount = amount;
}
}
public class Account {
private Money balance;
public Currency getBalance() {
return balance;
}
public BigDecimal getBalance() {
return balance;
}
public void setBalance(BigDecimal balance) {
this.balance = balance;
}
}
It’s like a Pavlovian reflex. Worse, it’s part of the JavaBean conventions, so that a lot of tools rely on them: ORM frameworks, serialization libraries, e.g. Jackson, mapping tools, e.g. MapStruct, etc.
Hence, if you rely on any of those tools, you have no choice. If you don’t, then you should probably think about whether you want to go this way or not.
Here’s an alternative (and simplified) design to the above class:
class Account {
// Field and getter
// NO SETTER!
public BigDecimal creditFrom(Account account, Money amount) {
// Check that currencies are compatible
// Do the credit
}
public BigDecimal debitFrom(Account account, Money amount) {
// Check that currencies are compatible
// Do the debit
}
}
Note that getter alternatives make for a more complex design without many added benefits. I’m willing to keep them if they don’t expose private data – either immutable objects or copies.
Abstractions everywhere
One of the first lessons I was taught in enterprise was that “good” developers always design their implementation around the following three components:
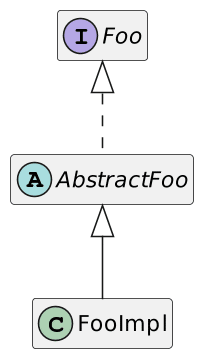
The problem is that FooImpl is the only Foo implementation, and it becomes apparent when you need to name the classes. The most common scheme is to prefix the abstract class with Abstract and suffix the concrete one with Impl. Another way to spot the issue is where to implement the method: between the abstract class and the concrete one, there’s no easy way to decide the best place.
Abstractions do lower coupling. However, coupling in applications has much less impact than in libraries, if at all.
Data Transfer Objects
I’ve used DTO for a very long time. One of my earliest blog posts is actually about DTOs, bean mapping, and the Dozer library to automate the mapping process. I even remember that a fellow architect advised me to design a dedicated class for each layer:
- Entities for the DAO layer
- Service objects for the layer of the same name
- View objects for the controller layer
Moreover, since PKs are not supposed to leak outside the database, we had a dedicated identifier column to pass around.
Did I hear you say over-engineering? Well, you might not be completely wrong.
It got me thinking about DTOs. They probably are a good idea if your view is very different from the underlying table(s). However, it was not the case in most, if not all, of the applications I worked on. They perfectly mimicked the database structure.
In that case, I’ll probably favour one of the techniques listed in this previous post.
Conclusion
In this post, I’ve described five techniques I’d probably not use anymore, or at least be very careful on the context I apply them to.
The more years you have behind you, the more mistakes you’ll probably have made. The idea is to build upon your experience to avoid repeating the same mistakes. As the Latin would say, errare humanum est, sed perseverare diabolicum.
- Quality Tools: humble servants or tyrants?
- Encapsulation: I don’t think it means what you think it means
- Are you guilty of overengineering?
- Alternatives to DTOs
Originally published at A Java Geek on March 13th , 2022
The post Lessons learned from previous projects appeared first on foojay.