 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
By its very nature, Big Data is too big to fit on a single machine. Datasets need to be partitioned across multiple machines. Each partition is assigned to one primary machine, with optional backup assignments. Hence, every machine holds multiple partitions. Most big data frameworks use a random strategy for assigning partitions to machines. If each computation job uses one partition, this strategy results in a good spreading of computational load across a cluster. However, if a job needs multiple partitions, there is a big chance that it needs to fetch partitions from other machines. Transferring data is always a performance penalty.
By: Ben Evans | InfoQ.
Apache Arrow puts forward a cross-language, cross-platform, columnar in-memory data format for data. It eliminates the need for serialization as data is represented by the same bytes on each platform and programming language. This common format enables zero-copy data transfer in big data systems, to minimize the performance hit of transferring data.
The goal of this article is to introduce Apache Arrow and get you acquainted with the basic concepts of the Apache Arrow Java library. The source code accompanying this article can be found here.
Typically, a data transfer consists of:
- serializing data in a format
- sending the serialized data over a network connection
- deserializing the data on the receiving side
Think for example about the communication between frontend and backend in a web application. Commonly, the JavaScript Object Notation (JSON) format is used to serialize data. For small amounts of data, this is perfectly fine. The overhead of serializing and deserializing is negligible, and JSON is human-readable which simplifies debugging. However, when data volumes increase, the serialization cost can become the predominant performance factor. Without proper care, systems can end up spending most of their time serializing data. Clearly, there are more useful things to do with our CPU cycles.
![]()
In this process, there is one factor we control in software: (de)serialization. Needless to say, there are a plethora of serialization frameworks out there. Think of ProtoBuf, Thrift, MessagePack, and many others. Many of them have minimizing serialization costs as a primary goal.
Despite their efforts to minimize serialization, there is inevitably still a (de)serialization step. The objects your code acts on, are not the bytes that are sent over the network. The bytes that are received over the wire, are not the objects the code on the other side crunches. In the end, the fastest serialization is no serialization.
Is Apache Arrow for me?
Conceptually, Apache Arrow is designed as a backbone for Big Data systems, for example, Ballista or Dremio, or for Big Data system integrations. If your use cases are not in the area of Big Data systems, then probably the overhead of Apache Arrow is not worth your troubles. You’re likely better off with a serialization framework that has broad industry adoption, such as ProtoBuf, FlatBuffers, Thrift, MessagePack, or others.
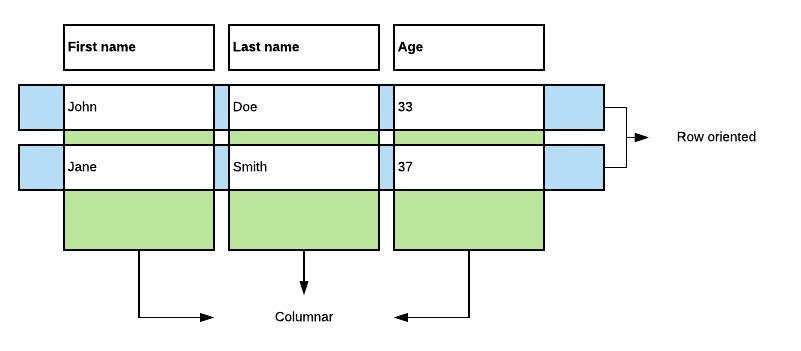
Coding with Apache Arrow is very different from coding with plain old Java objects, in the sense that there are no Java objects. Code operates on buffers all the way down. Existing utility libraries, e.g., Apache Commons, Guava, etc., are no longer usable. You might have to re-implement some algorithms to work with byte buffers. And last but not least, you always have to think in terms of columns instead of objects.
Building a system on top of Apache Arrow requires you to read, write, breathe, and sweat Arrow buffers. If you are building a system that works on collections of data objects (i.e., some kind of database), want to compute things that are columnar-friendly, and are planning to run this in a cluster, then Arrow is definitely worth the investment.
The integration with Parquet (discussed later) makes persistence relatively easy. The cross-platform, cross-language aspect supports polyglot microservice architectures and allows for easy integration with the existing Big Data landscape. The built-in RPC framework called Arrow Flight makes it easy to share/serve datasets in a standardized, efficient way.