 NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
NLJUG – Nederlandse Java User Group NLJUG – de Nederlandse Java User Group – is opgericht in 2003. De NLJUG verenigt software ontwikkelaars, architecten, ICT managers, studenten, new media developers en haar businesspartners met algemene interesse in alle aspecten van Java Technology.
Traditioneel zijn we gewend om JDBC (Java Database Connectivity) te gebruiken als we verbinding willen maken met relationele databases. Elke zichzelf respecterende relationele database heeft JDBC-drivers beschikbaar. Ook binnen applicatieservers speelt JDBC-configuratie vaak een prominente rol.
Auteur Maarten Smeets
JDBC echter is per specificatie blocking. Je doet een JDBC-verzoek en je wacht totdat deze klaar is. Als je een nieuw verzoek wilt uitvoeren zonder te wachten totdat het laatste verzoek is afgerond, kan je gebruik maken van verschillende threads en threadpools. Bij gebruik van JDBC in bijvoorbeeld een service is dit gebruik van threads vaak transparant voor de ontwikkelaar.
Gebruik van threads echter kost geheugen en CPU. Een processor core kan maar een beperkt aantal threads op hetzelfde moment bedienen. Als er meer threads nodig zijn dan beschikbaar, kan het zijn dat de processor tussen de threads die het moet bedienen, gaat switchen. Dit houdt in dat de toestand van een thread wordt opgeslagen en later weer hersteld zodat in de tussentijd ander werk gedaan kan worden. Dit switchen tussen threads vraagt processortijd. Daarnaast heeft een thread ook een bepaalde hoeveelheid geheugen in gebruik. Als er meer threads gebruikt worden, zal dit meer geheugen kosten.
Enter R2DBC. Reactive Relational Database Connectivity (R2DBC) biedt reactive APIs om met relationele databases te praten. R2DBC is opgekomen uit de behoefte van schaalbaarheid en de wens om grote aantallen verzoeken tegelijkertijd te kunnen verwerken zonder dat dit al te veel van de beschikbare hardware vraagt. R2DBC gaat efficiënter met threads om dan JDBC. Minder threads betekent dat er minder geheugen en CPU nodig zouden moeten zijn bij een vergelijkbare load als JDBC.
Eerst zien dan geloven
Om te kijken of deze claim waar wordt gemaakt, heb ik een aantal implementaties van een service gemaakt met dezelfde functionaliteit en benchmarks uitgevoerd. De REST service haalt gegevens op uit een Postgres database en retourneert deze. Om te kijken of het uitmaakt of je gebruik maakt van een volledige non-blocking stack of al mogelijk voordeel kan behalen door alleen een non-blocking component te gebruiken, heb ik de volgende implementaties naast elkaar gelegd. Wrk is gebruikt als HTTP benchmark tool en een PostgreSQL database als backend.
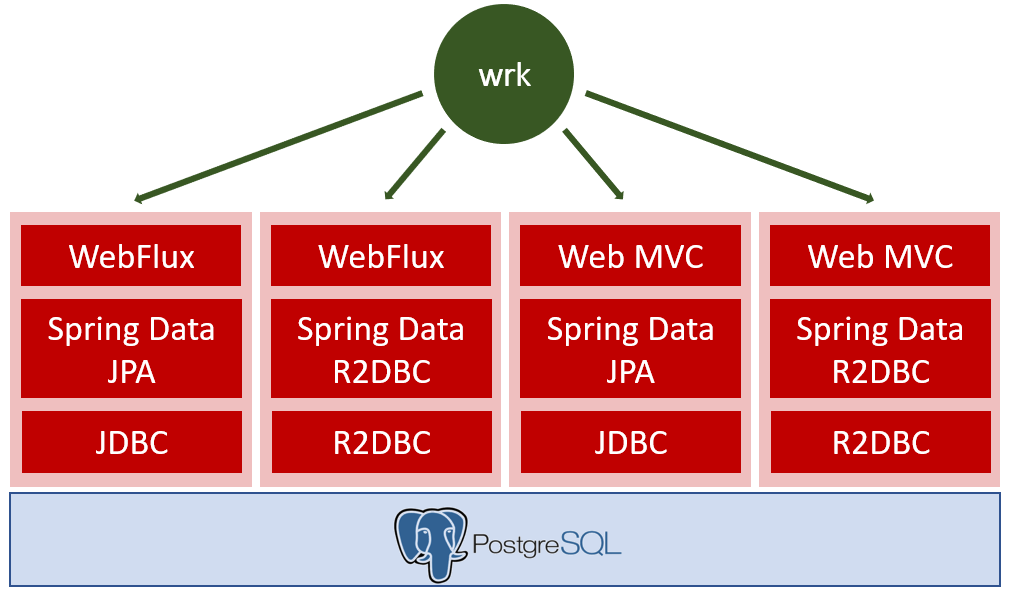
Waarom Spring? Naast dat Spring een populair framework is, had ik de wens een aantal implementaties naast elkaar te leggen wat met Spring eenvoudig is. Verschillende componenten waren al binnen het framework beschikbaar en klaar voor gebruik.
JPA wordt vaak gebruikt om Java objecten en operaties daarop te vertalen naar een relationeel database model (ORM). JPA is echter blocking. Als je de volledige stack non-blocking wilt hebben zonder zelf SQL te moeten gaan uitprogrammeren, is er een non-blocking alternatief voor JPA nodig. Spring biedt Spring Data R2DBC. Spring Data R2DBC biedt ORM en daarnaast repositories welke het makkelijk maken verscheidene database operaties met een minimale hoeveelheid boilerplate code te implementeren. Spring kent twee web frameworks: blocking Web MVC en non-blocking WebFlux. Deze zijn eenvoudig naast elkaar te leggen.
Uitdagingen
Bij de implementatie van de services liep ik tegen een aantal uitdagingen aan. WebFlux biedt een reactive API. Indien je met WebFlux bekend bent, ken je vast Flux en Mono. Spring Data R2DBC biedt reactive repositories welke methodes definiëren die netjes Flux en Mono objecten terug geven. WebFlux en Spring Data R2DBC sluiten dus goed op elkaar aan. Bij gebruik van Spring Web MVC past gebruik van niet-reactive repositories goed. Deze retourneren reguliere objecten op een blocking manier en deze kunnen vervolgens direct via Web MVC worden teruggegeven. Als je echter Web MVC wil gebruiken in combinatie met R2DBC, zal je eerst de reguliere objecten uit de geretourneerde Flux of Mono moeten halen. Het omgekeerde is waar als je achter WebFlux een JDBC-driver hangt. Een andere uitdaging was dat Spring Data R2DBC wat minder features biedt dan Spring Data JPA. Bij gebruik van R2DBC zal je dus wat meer moeten doen dan je mogelijk gewend bent bij gebruik van JDBC. Te denken valt aan:
- Gebruik van andere annotaties in je entiteiten
In plaats van JPA voor ORM gebruik je Spring Data R2DBC ORM.
Bijvoorbeeld gebruik je org.springframework.data.annotation.Id in plaats van javax.persistence.Id - Bepaalde functionaliteiten ontbreken in Spring Data R2DBC welke bijvoorbeeld wel in Spring Data JPA zitten zoals:
- Het uitvoeren van een SQL script bij starten.
In Spring kan je met een ConnectionFactoryInitializer een CompositeDatabasePopulator toevoegen op basis van een ClassPathResource wat een SQL file kan zijn. - Een connectionfactory aanmaken.
Hierbij moet je er vanzelfsprekend op letten dat je niet steeds een nieuwe connectionfactory aanmaakt op het moment dat deze wordt opgevraagd.
- Het uitvoeren van een SQL script bij starten.
Voorbeelden van hoe je dit kunt doen zijn opgenomen in de referenties. Een voordeel van geen gebruik (kunnen) maken van JPA is dat als je een fat JAR maakt, deze rond de 15MB kleiner wordt.
Metingen
Ik heb met wrk een HTTP benchmark op de implementaties losgelaten waarbij ik latency (responsetijden) en throughput (aantal verzoeken welke in een periode verwerkt kunnen worden) bepaald heb. Eerst heb ik de service laten opstarten en een korte tijd onder hoge load gezet. Dit zorgde dat de benodigde code al geladen was en de database connecties opgezet en gebruikt. Vervolgens is de daadwerkelijke test uitgevoerd. Proces CPU-gebruik is voor en na de test bepaald. Geheugen is aan het einde van de test bepaald. Er is gebruik gemaakt van OpenJDK 11.0.6 op een bare-metal Ubuntu 18.04 omgeving met minimale en maximale heap op 2Gb ingesteld. Ik heb de connectionpools op 100 ingesteld en expliciet 4 cores aan de load generator en aan de service toegekend. De database maakte gebruik van de overige beschikbare 4 cores. Concurrency heb ik gevarieerd in stappen tot 400. Bij een concurrency van 400 waren verschillen tussen de implementaties al goed zichtbaar. Elke meting is 20x uitgevoerd gedurende 120 secondes. In de grafieken zijn de gemiddeldes en standaarddeviaties weergegeven.
Resultaten
Een disclaimer is op zijn plaats. De resultaten zijn specifiek voor de gebruikte implementatie en hardware. Ze zullen niet exact te reproduceren zijn op een ander systeem of in een andere omgeving. Ik heb naar een aantal variabelen gekeken. Het is niet uitgesloten dat er andere variabelen zijn die ook een grote invloed op het gedrag van de services kunnen hebben. Gebruik de resultaten dus als inspiratie of je mogelijk profijt zou kunnen hebben van het gebruik van R2DBC. Kijk vervolgens zelf wat het je mogelijk kost en oplevert om JDBC te gaan vervangen en maak een eigen weloverwogen keuze.
Responsetijden
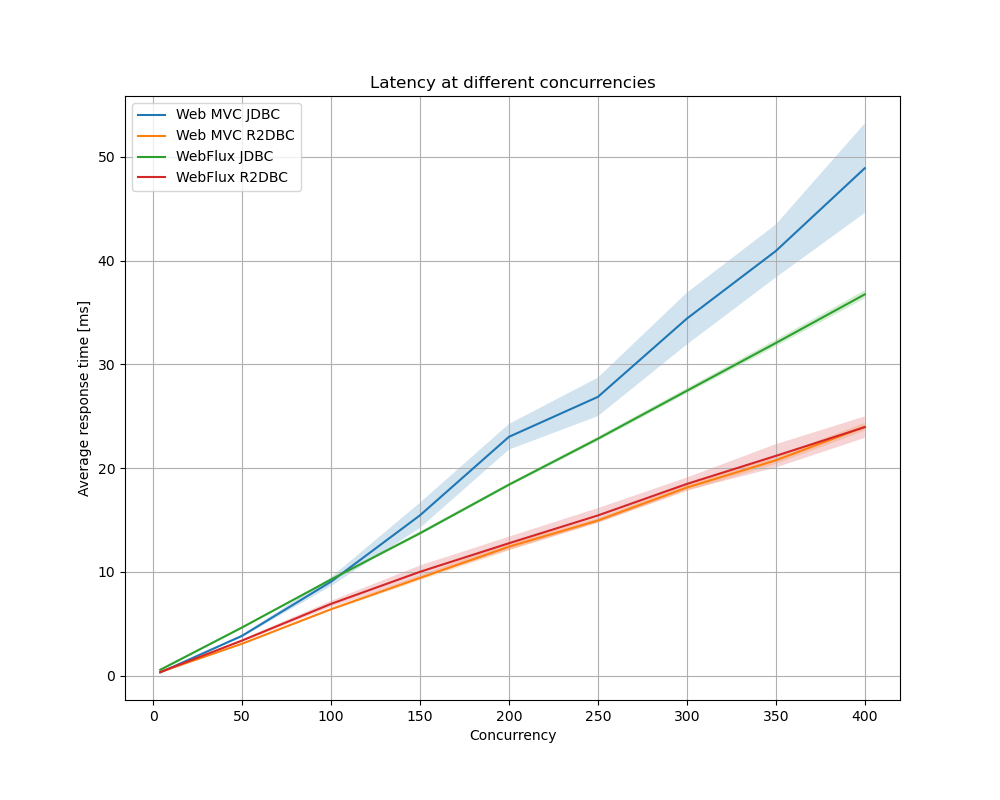
Het is interessant om te zien dat bij hogere concurrency R2DBC duidelijk lagere responsetijden geeft dan JDBC. Bij gebruik van R2DBC maakt het weinig uit of je nu Web MVC of WebFlux gebruikt. Als je JDBC gebruikt in combinatie met Web MVC en JDBC wilt blijven gebruiken, kan je bij hogere concurrency winst halen op responsetijden door over te stappen op WebFlux.
Throughput
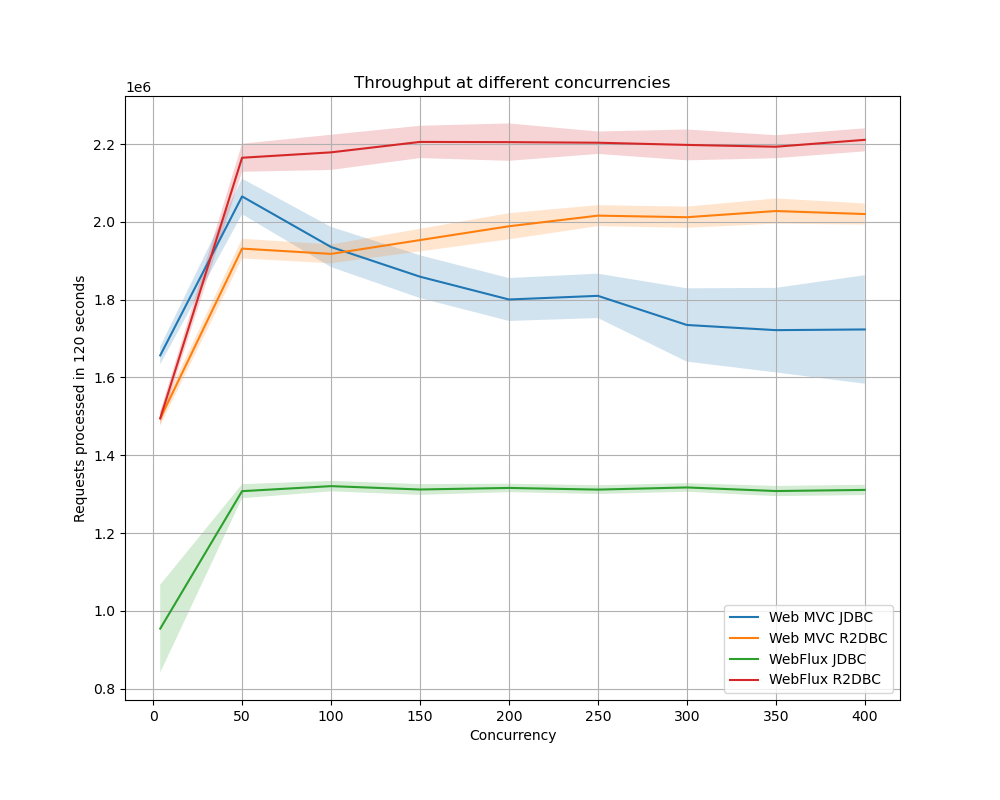
Bij lage concurrency geeft Web MVC met JDBC de hoogste throughput. Bij hoger wordende concurrency, wordt deze echter ingehaald eerst door WebFlux met R2DBC en vervolgens door Web MVC met R2DBC. WebFlux met JDBC blijkt voor een goede throughput bij elke concurrency geen verstandige keuze.
CPU-gebruik
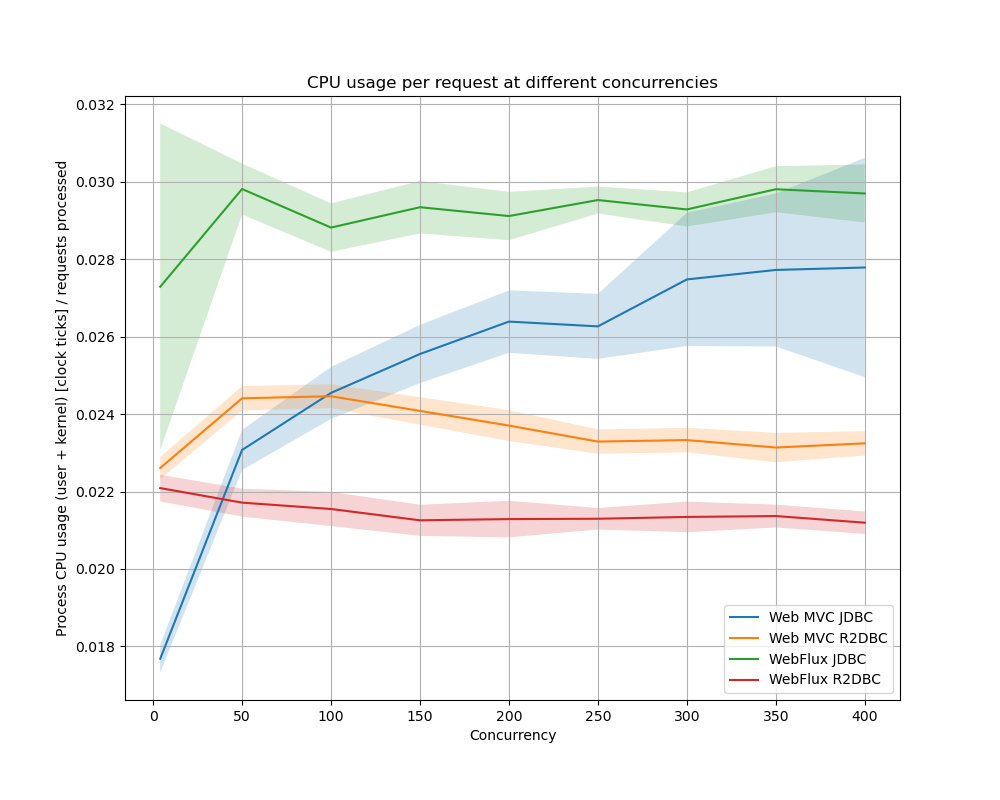
Door te kijken naar hoeveel CPU-tijd er gemiddeld nodig is om een enkel request te verwerken, is een beeld te krijgen van de efficiëntie van de implementatie.
WebFlux in combinatie met JDBC heeft het meeste CPU-tijd nodig om een enkel verzoek te verwerken. WebFlux met R2DBC bleek het meest efficiënt met zijn CPU-tijd om te gaan. Web MVC met JDBC wordt minder efficiënt bij hogere concurrency terwijl de andere implementaties een stabielere efficiëntie hebben.
Geheugengebruik
Web MVC met R2DBC gebruikt het meeste geheugen. We hebben echter eerder gezien dat deze combinatie ook de meeste verzoeken in een periode kon verwerken. In de onderstaande grafiek is het gemiddeld geheugengebruik per request geplot om een idee te kunnen krijgen van de efficiëntie.
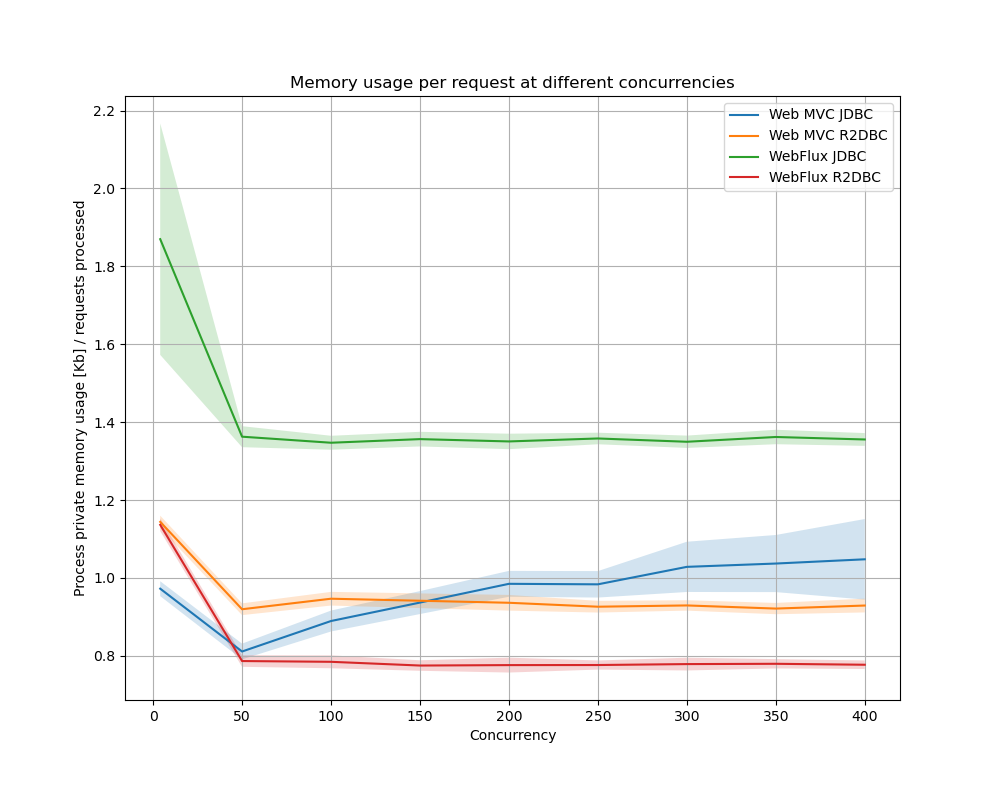
WebFlux met R2DBC gebruikt (bij hoge concurrency) het minst geheugen om een enkel verzoek af te handelen. WebFlux met JDBC het meest. Web MVC met JDBC heeft bij lage concurrency het minst geheugen nodig om een verzoek af te handelen. Dit neemt wel toe als de concurrency toeneemt terwijl implementaties waar een non-blocking web framework of driver gebruikt wordt, stabiel zijn.
Afsluitend
Hoewel R2DBC veelbelovend is, zitten er op dit moment nog wat uitdagingen aan het implementeren. De implementaties die er zijn, zijn relatief jong. Het aanroepen van stored procedures is bijvoorbeeld een feature welke nog niet in versie 0.8 van de standaard aanwezig is. Er zijn ook nog niet voor elke relationele database drivers beschikbaar. Op dit moment is er nog geen Oracle database driver. Oracle heeft aangegeven in te willen zetten op Fibers (Project Loom) en niet op R2DBC. Oracle heeft een periode aan een concurrerende standaard, ADBA gewerkt, maar daar zijn ze mee gestopt. Voor de komende versie van de JDBC-drivers zijn reactive extensions beloofd.
Spring biedt Spring Data R2DBC welke een goed startpunt is om met R2DBC te experimenteren. Deze biedt ORM zodat je niet met de hand SQL hoeft uit te gaan programmeren en sluit goed aan op Spring WebFlux.
R2DBC biedt zelfs op dit moment al duidelijke voordelen. Met name op hogere concurrency zijn lagere responsetijden en hogere throughput te behalen vergeleken met JDBC. Op hogere concurrency zijn bij R2DBC geheugen en CPU wat nodig is om een enkel verzoek te kunnen verwerken, minder en stabieler. JDBC in combinatie met Web MVC wordt bij hogere concurrency minder efficiënt. Om voordeel te halen uit R2DBC is het niet nodig om een volledige non-blocking stack te gebruiken maar het helpt wel. WebFlux met R2DBC werkt het best op hogere concurrency. Daarnaast programmeert een volledige non-blocking of blocking stack ook makkelijker dan een deel non-blocking en een deel blocking. Spring Data R2DBC reactive repositories bieden precies wat je met WebFlux als antwoord van een service call terug zou willen geven. Dit is ook van toepassing op Web MVC met JDBC.
Als je applicatie niet grote aantallen simultane verzoeken te verwerken krijgt, is het wellicht verstandiger op dit moment om bij de oude vertrouwde en goed ondersteunde JDBC te blijven. Bij lage concurrency doet JDBC (zelfs in combinatie met Web MVC) het op bijna elk vlak (nog?) beter dan R2DBC.
Referenties
Spring Data R2DBC
https://spring.io/projects/spring-data-r2dbc
Homepage van het R2DBC project
Gebruikte R2DBC voorbeeld implementaties en testscripts
 Bio
Bio
Maarten Smeets is Software Architect bij het CJIB. Hij deelt zijn kennis en enthousiasme graag op conferenties, in workshops, blogs en artikelen.